哈佛结构
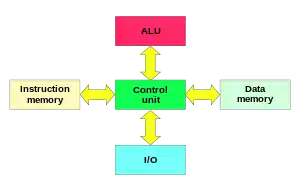
哈佛架构(英語:)是一种将程序指令储存和数据储存分开的存储器结构(Split Cache)。这一词起源于Harvard Mark I型继电器式计算机,它存储指令(24位)在纸带上和数据于机电计数器上。 中央处理器首先到程序指令储存器中读取程序指令内容,解码后得到数据地址,再到相应的数据储存器中读取数据,并进行下一步的操作(通常是执行)。程序指令储存和数据储存分开,数据和指令的储存可以同时进行,可以使指令和数据有不同的数据宽度,如Microchip公司的PIC16芯片的程序指令是14位宽度,而数据是8位宽度。程序需要由操作者加载;处理器无法自行初始化。
如今,大多数处理器由于性能原因性能实现了这种独立信号通路的结构,但实际上大多是应用了改进的哈佛结构,所以它们可以支持从磁盘将一个程序作为数据加载并执行的任务。
哈佛架构的微处理器通常具有较高的执行效率。其程序指令和数据指令分开组织和储存的,执行时可以预先读取下一条指令。
目前使用哈佛架构的中央处理器和微控制器有很多,除了上面提到的Microchip公司的PIC系列芯片,还有摩托罗拉公司的MC68系列、Zilog公司的Z8系列、Atmel公司的AVR系列和安谋公司的ARM9、ARM10和ARM11。
内存的详细信息
在哈佛架构,两个寄存器不需要有共同的特征。特别是,字宽、定时、实现技术和内存地址都可以不同。在一些系统中,指令可以存储在只读存储器(ROM)中,而数据存储器一般需要读写存储器(RAM等)。在一些系统中,指令存储器比数据存储器多,因此指令地址比数据地址更宽。
与冯诺依曼架构的对比
纯冯诺依曼架构下的CPU可以读取指令或读/写内存数据,它们都不能使指令和数据同时使用同一個的总线系统。使用哈佛结构的计算机中CPU,即使没有缓存的情况下也可以在读取指令的同时进行数据访问。由于指令和数据访问不使用同一个内存通道,因此哈佛结构的计算机可以在相同的電路複雜度下有更好的表現。
同时,哈佛架构机拥有不同的代码和数据的地址空间:指令的零地址和数据的零地址是不同的。指令的零地址可能是二十四位的值,而数据的零地址可能是一个八位字节,而非二十四位值的一部分。
与改进的哈佛架构的对比
改进的哈佛架构机更像哈佛架构机,但它放松了指令和数据之间严格分离的这一特征,仍然允许CPU同时访问两个(或更多)内存总线。最常见的修改包括由公共地址空间支持的单独指令和数据高速缓存。当它作为一个纯粹的哈佛机时,CPU通过高速缓存来执行指令。当访问外部存储器时,它的作用就像一个冯·诺依曼机(代码可以像数据一样移动,像是一个功能强大的技能)。这一改良在现代处理器是普遍存在的,例如ARM体系结构、Power Architecture和x86处理器。它有时被称为哈佛架构,忽略了它实际上被“修改”的事实。
另一种修改提供了指令存储器(例如ROM或闪存)与CPU之间的通路,以允许来自指令存储器的字被视为只读数据。该技术用于某些微控制器,包括Atmel的AVR。这允许访问诸如文本字符串或函数表之类的常量数据,而无需首先将其复制到数据存储器中,从而为读/写变量保留稀缺(且耗电的)数据存储器。特殊的机器语言指令提供了从指令存储器中读取数据的功能。(这是不同于指令本身嵌入常数的数据,虽然对于单个常量来说,两种机制可以相互替代。)
速度
近年来,CPU的速度已经提速了许多次以同步主存储器的存取速度。要注意减少内存访问次数的数量以保持性能。例如,每一个指令在CPU运行需要访问内存,增加计算机CPU没有任何速度提升的问题叫做内存限制。可能使内存非常快,但由于内存成本,电源和信号路由的原因这类内存数目很少。解决的办法是提供少量的快速存储器称为CPU缓存以存放最近访问过的数据。CPU提取缓存中的数据速度要比缓存提取主要寄存器数据的速度更快。
内部与外部的设计
现代高性能CPU芯片在设计上包含了哈佛和冯诺依曼结构的特点。特别是,“拆分缓存”这种改进型的哈佛架构版本是很常见的。 CPU的缓存分为指令缓存和数据缓存。CPU访问缓存时使用哈佛体系结构。然而当高速缓存未命中时,数据从主存储器中检索,却并不分为独立的指令和数据部分,虽然它有独立的内存控制器用于访问RAM,ROM和(NOR)闪存。 因此,在一些情况下可以看到冯诺依曼架构,比如当数据和代码通过相同的内存控制器时,这种硬件通过哈佛架构在缓存访问或至少主内存访问方面提高了执行效率。 此外,在写非缓存区之后,CPU经常拥有写缓存使CPU可以继续执行。当指令被CPU当作数据写入,且软件必须确保在试图执行这些刚写入的指令之前,高速缓存(指令和数据)和写缓存是同步的,这时冯诺依曼结构的内存特点就出现了。
哈佛结构的现代应用
纯粹的哈佛架构同时访问多个存储系统的主要优点是由哈佛处理器利用现代CPU缓存系统。相对纯的哈佛架构机主要用于在应用中的取舍,就像忽略缓存的成本和节省功率,大于编程在不同的代码和数据的地址空间的不利。
- 数字信号处理器(DSPs) 一般执行少,高度优化的音频或视频处理算法。他们避免缓存,因为他们的行为必须非常重现。应对多地址空间的困难,执行速度是次要的问题。因此,一些DSP功能在不同的地址空间的多个数据存储器便于SIMD和VLIW处理。德克萨斯仪器TMS320 C55x处理器,具有多个并行数据总线(双写,三读)和指令总线。
- 单片机的特点是具有少量的程序(闪存)、数据存储器(SRAM),没有缓存,并利用哈佛架构的并行高速处理指令和数据的访问。分开存储的程序和数据存储器可能具有不同的位宽,例如使用16位指令和8位宽的数据。这也意味着指令预取可以与其他活动同时进行。例子包括,Atmel的AVR和Microchip的 PIC。
即使在这种情况下,它是为了访问程序存储器只读表的数据使用特殊指令或重新编程;这些处理器是改进的哈佛架构的处理器。
