資料倉儲
在计算机领域,数据仓库(英語:,也称为企业数据仓库)是用于报告和数据分析的系统,被认为是商业智能的核心组件。[1] 数据仓库是来自一个或多个不同源的集成数据的中央存储库。数据仓库将当前和历史数据存储在一起[2],用于为整个企业的员工创建分析报告。[3]
| 数据转换/源转换 |
|---|
| 概念 |
| 语言 |
|
| 技术和转换 |
|
| 应用程序 |
| 应用领域 |
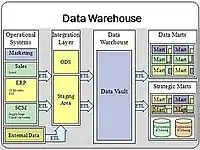
存储在仓库中的数据从运行系统(例如营销或销售)上傳。这些数据可能会通过一个ODS数据库,并且可能需要进行额外操作的数据清理[2],以确保数据质量,然后才能在数据仓库中用于报告。
典型的基于提取、转换、加载(ETL)的数据仓库[4]使用分级、数据集成和访问层来存放其关键功能。分级层或分级数据库存储从每个不同的源数据系统中提取的原始数据。集成层通过转换来自分级层的数据,将不同的数据集合在一起,通常将转换后的数据存储在ODS数据库中。然后将集成的数据转移到另一个数据库(通常称为数据仓库数据库),在这个数据库中,数据被分为层次组(通常称为维度),并被分成事实和聚合事实。事实和维度的组合有时被称为星型模式。访问层帮助用户检索数据。[5]
数据的主要来源被清理、转换、分类,并提供给管理人员和其他商业专业人员用于数据挖掘、線上分析處理、市场研究和决策支持。[6] 然而,检索和分析数据、提取、转换和装载数据以及管理数据字典的方法也被认为是数据仓库系统的基本组成部分。许多数据仓库的文献都使用了这个更广泛的语境。因此,数据仓库的扩展定义包括商业智能工具、提取、转换和加载数据到存储库的工具,以及管理和检索元数据的工具。
較簡易的解釋方式
資料倉儲是一種資訊系統的資料儲存理論,此理論強調利用某些特殊資料儲存方式,讓所包含的資料,特別有利於分析處理,以產生有價值的資訊並依此作決策。
利用資料倉儲方式所存放的資料,具有一但存入,便不隨時間而更動的特性,同時存入的資料必定包含時間屬性,通常一個資料倉儲皆會含有大量的歷史性資料,並利用特定分析方式,自其中發掘出特定資訊。
較學術的解釋方式
資料倉儲 ,由資料倉儲之父W.H.Inmon於1990年提出,主要功能乃是將組織透過資訊系統之線上交易處理(OLTP)經年累月所累積的大量資料,透過資料倉儲理論所特有的資料儲存架構,作一有系統的分析整理,以利各種分析方法如線上分析處理(OLAP)、資料採礦(Data Mining)之進行,並進而支援如決策支援系統(DSS)、主管資訊系統(EIS)之建立,幫助決策者能快速有效的自大量資料中,分析出有價值的資訊,以利決策擬定及快速回應外在環境變動,幫助建構商業智慧(BI)。
一般來說,資料倉儲可由關聯式資料庫,或專為資料倉儲開發的多維度資料庫建立,若由多維度資料庫建立而成,其架構可分為星狀及雪花狀架構,包含數個維度資料表,及一個事實資料表。
資料倉儲的建制不僅只是資訊工具技術面的運用,在規畫和執行面更需對產業知識、行銷管理、市場定位、策略規畫等相關條件有深入的了解,才能真正發揮資料倉儲以及後續分析工具的價值,提升組織競爭力。
資料倉儲的特性
- 主題導向(Subject-Oriented)
- 有別於一般OLTP系統,資料倉儲的資料模型設計,著重將資料按其意義歸類至相同的主題區(subject area),因此稱為主題導向。舉例如Party、Arrangement、Event、Product等。
- 整合性(Integrated)
- 資料來自企業各OLTP系統,在資料倉儲中是整合過且一致的。
- 時間差異性(Time-Variant)
- 資料的變動,在資料倉儲中是能夠被紀錄以及追蹤變化的,有助於能反映出能隨著時間變化的資料軌跡。
- 不變動性(Nonvolatile)
- 資料一旦確認寫入後是不會被取代或刪除的,即使資料是錯誤的亦同。(i.e.錯誤的後續修正,便可因上述時間差異性的特性而被追蹤)
ODS、資料倉儲和資料超市之異同
Operational data store(ODS)、資料倉儲和資料超市三者相同之處在於均不屬於任一OLTP系統,並且都是以資料導向的設計而非流程(process)導向。
相異之處在於,ODS的特性較著重於戰術性查詢,變動性大。資料倉儲通常為企業層級,用來解答即興式、臨時性的問題。而資料超市則較偏向解決特定單位或部門的問題,部分採用維度模型(dimensional model)。
資料採礦、OLAP和資料倉儲
資料倉儲可以作為資料採礦和OLAP等分析工具的資料來源,由於存放於資料倉儲中的資料,必需經過篩選與轉換,因此可以避免分析工具使用錯誤的資料,而得到不正確的分析結果。
資料採礦和OLAP同為分析工具,其差別在於OLAP提供使用者一便利的多維度觀點和方法,以有效率的對資料進行複雜的查詢動作,其預設查詢條件由使用者預先設定,而資料採礦,則能由資訊系統主動發掘資料來源中,未曾被察覺的隱藏資訊,和透過使用者的認知以產生知識。
資料採礦(Data Mining)技術是經由自動或半自動的方法探勘及分析大量的資料,以建立有效的模型及規則,而企業透過資料採礦更瞭解他們的客戶,進而改進他們的行銷、業務及客服的運作。 資料採礦是資料倉儲的一種重要運用。基本上,它是用來將你的資料中隱藏的資訊挖掘出來,所以 Data Mining 其實是所謂的 Knowledge Discovery 的一部份,Data Mining 使用了許多統計分析與 Modeling 的方法,到資料中尋找有用的特徵(Patterns)以及關連性(Relationships)。 Knowledge Discovery 的過程對 Data Mining 的應用成功與否有重要的影響,只有它才能確保 Data Mining 能獲得有意義的結果。
参考文献
- Dedić, Nedim; Stanier, Clare. Hammoudi, Slimane; Maciaszek, Leszek; Missikoff, Michele M. Missikoff; Camp, Olivier; Cordeiro, José , 编. . International Conference on Enterprise Information Systems, 25–28 April 2016, Rome, Italy (PDF). Proceedings of the 18th International Conference on Enterprise Information Systems (ICEIS 2016) 1 (SciTePress). 2016: 196–206. ISBN 978-989-758-187-8. doi:10.5220/0005858401960206.
- . blog.rjmetrics.com. [2017-04-30].
- . spotlessdata.com. [2017-04-30].
- . spotlessdata.com. [2017-04-30].
- Patil, Preeti S.; Srikantha Rao; Suryakant B. Patil. . IJCA Proceedings on International Conference and workshop on Emerging Trends in Technology (ICWET) (Foundation of Computer Science). 2011, 9 (6): 33–37.
- Marakas & O'Brien 2009
