OpenMP
(Open Multi-Processing)是一套支持跨平台共享内存方式的多线程并发的编程API,使用C,C++和Fortran语言,可以在大多数的处理器体系和操作系统中运行,包括Solaris, AIX, HP-UX, GNU/Linux, Mac OS X, 和Microsoft Windows。包括一套编译器指令、库和一些能够影响运行行为的环境变量。
| 原作者 | OpenMP Architecture Review Board[1] |
|---|---|
| 開發者 | OpenMP Architecture Review Board[1] |
| 穩定版本 | 5.0 (2018年11月8日) |
| 编程语言 | C, C++, Fortran |
| 操作系统 | 跨平台 |
| 系統平台 | 跨平台 |
| 类型 | API |
| 许可协议 | 多种[2] |
| 网站 | http://openmp.org |
OpenMP采用可移植的、可扩展的模型,为程序员提供了一个简单而灵活的开发平台,从标准桌面电脑到超级计算机的并行应用程序接口。
混合并行编程模型构建的应用程序可以同时使用OpenMP和MPI,或更透明地通过使用OpenMP扩展的非共享内存系统上运行的计算机集群。
OpenMP是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受的,用于共享内存并行系统的多线程程序设计的一套指导性注释(Compiler Directive)。OpenMP支持的程式語言包括C语言、C++和Fortran;而支持OpenMP的编译器包括Sun Studio和Intel Compiler,以及開放源碼的GCC、LLVM和Open64編譯器。OpenMP提供了对并行算法的高层的抽象描述,程序员通过在原始碼中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMP时,程序又可退化为通常的程序(一般为串行),程式码仍然可以正常运作,只是不能利用多线程来加速程序执行。
介绍
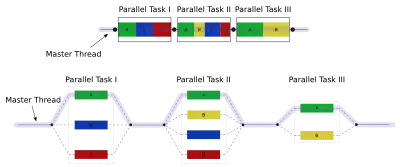
OpenMP是一个跨平台的多线程实现,主线程(顺序的执行指令)生成一系列的子线程,并将任务划分给这些子线程进行执行。这些子线程并行的运行,由运行时环境将线程分配给不同的处理器。
要进行并行执行的代码片段需要进行相应的标记,用预编译指令使得在代码片段被执行前生成线程,每个线程会分配一个id,可以通过函数(called omp_get_thread_num())来获得该值,该值是一个整数,主线程的id为0。在并行化的代码运行结束后,子线程join到主线程中,并继续执行程序。
默认情况下,各个线程独立地执行并行区域的代码。可以使用Work-sharing constructs来划分任务,使每个线程执行其分配部分的代码。通过这种方式,使用OpenMP可以实现任务并行和数据并行。
运行时环境分配给每个处理器的线程数取决于使用方法、机器负载和其他因素。线程的数目可以通过环境变量或者代码中的函数来指定。在C/C++中,OpenMP的函数都声明在头文件omp.h中。
历史
OpenMP Architecture Review Board (ARB)于1997年10月发布了OpenMP for Fortran 1.0。次年的10月,发布了C/C++的标准。2000年,发布了Fortran语言的2.0版本,并于2002年发布了C/C++语言的2.0版本。2005年,包含Fortran和C/C++的2.5版本发布了。
在2008年5月发布了3.0版。3.0中的新功能包括任务(tasks)和任务结构(task construct)的概念。这些新功能总结在OpenMP3.0规范的附录F中。 OpenMP规范的3.1版于2011年7月9日发布。
4.0版本在2013年7月发布,它增加或改进以下功能:支持加速器,原子性,错误处理,线程关联,任务扩展,减少用户定义的SIMD支持和Fortran 2003的支持。
特色
OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。同时,使用OpenMP也提供了更强的灵活性,可以较容易的适应不同的并行系统配置。线程粒度和负载平衡等是传统多线程程序设计中的难题,但在OpenMP中,OpenMP库从程序员手中接管了部分这两方面的工作。
語法
#pragma omp <directive> [clause[[,] clause] ...]
directive
其中,directive共11个:
- atomic 内存位置將會原子更新(Specifies that a memory location that will be updated atomically.)
- barrier 线程在此等待,直到所有的线程都執行到此barrier。用來同步所有线程。
- critical 其后的代码块为临界区,任意时刻只能被一個线程執行。
- flush 所有线程对所有共享对象具有相同的内存视图(view of memory)
- for 用在for循环之前,把for循环并行化由多个线程执行。循环变量只能是整型
- master 指定由主线程來執行接下來的程式。
- ordered 指定在接下來的代码块中,被并行化的 for循环將依序執行(sequential loop)
- parallel 代表接下來的代码块將被多个线程并行各执行一遍。
- sections 將接下來的代码块包含将被并行执行的section块。
- single 之後的程式將只會在一個线程(未必是主线程)中被执行,不會被并行执行。
- threadprivate 指定一个变量是线程局部存储(thread local storage)
clause
共计13个clause:
- copyin 讓threadprivate的变量的值和主线程的值相同。
- copyprivate 不同线程中的变量在所有线程中共享。
- default Specifies the behavior of unscoped variables in a parallel region.
- firstprivate 对于线程局部存储的变量,其初值是进入并行区之前的值。
- if 判斷條件,可用來決定是否要并行化。
- lastprivate 在一个循环并行执行结束后,指定变量的值为循环体在顺序最后一次执行时取得的值,或者#pragma sections在中,按文本顺序最后一个section中执行取得的值。
- nowait 忽略barrier的同步等待。
- num_threads 設定线程数量的數量。默认值为当前计算机硬件支持的最大并发数。一般就是CPU的内核数目。超线程被操作系统视为独立的CPU内核。
- ordered 使用於 for,可以在將循环并行化的時候,將程式中有標記 directive ordered 的部份依序執行。
- private 指定变量为线程局部存储。
- reduction Specifies that one or more variables that are private to each thread are the subject of a reduction operation at the end of the parallel region.
- schedule 設定for循环的并行化方法;有 dynamic、guided、runtime、static 四種方法。
- schedule(static, chunk_size) 把chunk_size数目的循环体的执行,静态依序指定给各线程。
- schedule(dynamic, chunk_size) 把循环体的执行按照chunk_size(缺省值为1)分为若干组(即chunk),每个等待的线程获得当前一组去执行,执行完后重新等待分配新的组。
- schedule(guided, chunk_size) 把循环体的执行分组,分配给等待执行的线程。最初的组中的循环体执行数目较大,然后逐渐按指数方式下降到chunk_size。
- schedule(runtime) 循环的并行化方式不在编译时静态确定,而是推迟到程序执行时动态地根据环境变量OMP_SCHEDULE 來決定要使用的方法。
- shared 指定变量为所有线程共享。
OpenMP的库函数
OpenMP定义了20多个库函数:
1.void omp_set_num_threads(int _Num_threads);
在后续并行区域设置线程数,此调用只影响调用线程所遇到的同一级或内部嵌套级别的后续并行区域.说明:此函数只能在串行代码部分调用.
2.int omp_get_num_threads(void);
返回当前线程数目.说明:如果在串行代码中调用此函数,返回值为1.
3.int omp_get_max_threads(void);
如果在程序中此处遇到未使用 num_threads() 子句指定的活动并行区域,则返回程序的最大可用线程数量.说明:可以在串行或并行区域调用,通常这个最大数量由omp_set_num_threads()或OMP_NUM_THREADS环境变量决定.
4.int omp_get_thread_num(void);
返回当前线程id.id从1开始顺序编号,主线程id是0.
5.int omp_get_num_procs(void);
返回程序可用的处理器数.
6.void omp_set_dynamic(int _Dynamic_threads);
启用或禁用可用线程数的动态调整.(缺省情况下启用动态调整.)此调用只影响调用线程所遇到的同一级或内部嵌套级别的后续并行区域.如果 _Dynamic_threads 的值为非零值,启用动态调整;否则,禁用动态调整.
7.int omp_get_dynamic(void);
确定在程序中此处是否启用了动态线程调整.启用了动态线程调整时返回非零值;否则,返回零值.
8.int omp_in_parallel(void);
确定线程是否在并行区域的动态范围内执行.如果在活动并行区域的动态范围内调用,则返回非零值;否则,返回零值.活动并行区域是指 IF 子句求值为 TRUE 的并行区域.
9.void omp_set_nested(int _Nested);
启用或禁用嵌套并行操作.此调用只影响调用线程所遇到的同一级或内部嵌套级别的后续并行区域._Nested 的值为非零值时启用嵌套并行操作;否则,禁用嵌套并行操作.缺省情况下,禁用嵌套并行操作.
10.int omp_get_nested(void);
确定在程序中此处是否启用了嵌套并行操作.启用嵌套并行操作时返回非零值;否则,返回零值.
互斥锁操作 嵌套锁操作 功能
11.void omp_init_lock(omp_lock_t * _Lock); 12. void omp_init_nest_lock(omp_nest_lock_t * _Lock);
初始化一个(嵌套)互斥锁.
13.void omp_destroy_lock(omp_lock_t * _Lock); 14.void omp_destroy_nest_lock(omp_nest_lock_t * _Lock);
结束一个(嵌套)互斥锁的使用并释放内存.
15.void omp_set_lock(omp_lock_t * _Lock); 16.void omp_set_nest_lock(omp_nest_lock_t * _Lock);
获得一个(嵌套)互斥锁.
17.void omp_unset_lock(omp_lock_t * _Lock); 18.void omp_unset_nest_lock(omp_nest_lock_t * _Lock);
释放一个(嵌套)互斥锁.
19.int omp_test_lock(omp_lock_t * _Lock); 20.int omp_test_nest_lock(omp_nest_lock_t * _Lock);
试图获得一个(嵌套)互斥锁,并在成功时放回真(true),失败是返回假(false).
21.double omp_get_wtime(void);
获取wall clock time,返回一个double的数,表示从过去的某一时刻经历的时间,一般用于成对出现,进行时间比较. 此函数得到的时间是相对于线程的,也就是每一个线程都有自己的时间.
22.double omp_get_wtick(void);
得到clock ticks的秒数.
例子
在 omp parallel 段內的程序代碼由多線程來執行:
int main(int argc, char* argv[])
{
#pragma omp parallel
printf("Hello, world.\n");
return 1;
}
執行結果
% gcc omp.c (由單線程來執行) % ./a.out Hello, world. % gcc -fopenmp omp.c (由多線程來執行) % ./a.out Hello, world. Hello, world. Hello, world. Hello, world.
環境變量
OpenMP可以使用環境變量 OMP_NUM_THREADS以控制執行線程的數量。
例子
% gcc -fopenmp omp.c % setenv OMP_NUM_THREADS 2(由2線程來執行) setenv是CSH的指令 在bash shell 環境中 要用export % export OMP_NUM_THREADS=2 (由2線程來執行) % ./a.out Hello, world. Hello, world.
优点和缺点
优点
- 可移植的多线程代码(在C/C++和其他语言中,人们通常为了获得多线程而调用特定于平台的原语)
- 简单,没必要象MPI中那样处理消息传递
- 数据分布和分解由指令自动完成
- 增量并行,一次可以只在代码的一部分执行,对代码不需要显著的改变
- 统一的顺序执行和并行执行的代码,在顺序执行编译器上,OpenMP的执行按照注释进行对待;
- 在一般情况下,使用OpenMP并行时原始的(串行)代码语句不需要进行修改,这减少不经意间引入错误的机会。
- 同时支持粗粒度和细粒度的并行
- 可以在GPU上使用[3]
缺点
- 存在引入难以调试的同步错误和竞争条件的风险
- 目前,只能在共享内存的多处理器平台高效运行
- 需要一个支持OpenMP的编译器
- 可扩展性是受到内存架构的限制
- 不支持比较和交换
- 缺乏可靠的错误处理
- 缺乏对线程与处理器映射的细粒度控制
- 很容易出现一些不能共享的代码
- 多线程的可执行文件的启动需要更多的时间,可能比单线程的运行的慢,因此,使用多线程一定要有其他有优势的地方
- 很多情况下使用多线程不仅没有好处,还会带来一些额外消耗
编译器支持
主流C/C++编译器,如gcc与visual C++,都内在支持OpenMP。一般都必须在程序中#include <omp.h>
gcc编译时需使用编译选项-fopenmp。但是,如果编译为目标文件与链接生成可执行文件是分开为两步操作,那么链接时需要给出附加库gomp,否则会在链接时报错“undefined reference to `omp_get_thread_num'"。
Visual C++需要在IDE的编译选项->语言->支持OpenMP。这实际上使用了编译选项/openmp
