蛋白质结构预测
蛋白质结构预测(英語:)是指从蛋白质的氨基酸序列中预测蛋白质的三维结构。也就是说,从蛋白质的一级结构预测它的折叠和二级、三级、四级结构。结构预测与蛋白质设计的反问题有着根本的不同。蛋白质结构预测是生物信息学与理论化学所追求的最重要目标之一;它在医学上(例如,在药物设计)和在生物技术上(例如,新的酶的设计)都是非常重要的。每隔两年,当前蛋白质结构预测技术的性能在蛋白质结构预测技术的关键测试(CASP)实验中被评测。蛋白质结构预测的网络服务器连续的评测是由社区项目CAMEO3D执行。
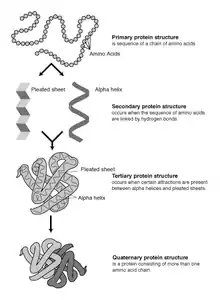
蛋白质结构和术语
蛋白质是由氨基酸链通过肽键连接在一起。与α碳原子相连的C-N键和C-C键相对旋转,产生了蛋白质主链的多种构象,也正是这些构象变化造成了蛋白质三维结构上的差异。每一个氨基酸的主链都是极性的,即 碳氧双键上的碳原子带正电性、氧原子带负电性(δ+ C=O δ-),氧原子可以作为氢键受体;氮氢单键有(δ- N-H δ+),氮原子可以作为氢键供体。这些基团在蛋白质结构中便可以相互作用。根据侧链结构的不同可以分为20种常见氨基酸,各自在蛋白质中扮演着重要的角色。甘氨酸(Glycine)的角色往往很特殊,因为它的侧链是最小的,只有一个氢原子,没有侧链的空间位阻就增加了主链的局部灵活性。半胱氨酸(Cysteine)可以与另一个半胱氨酸发生交联反应形成二硫键,使蛋白质整体更加稳定。
蛋白质结构的形成以二级结构元素(Secondary Structure Elements, SSE)为基础,二级结构中有α螺旋和β折叠,它们共同构成了蛋白质链的三级结构。在这些常见的二级结构中,相邻的氨基酸之间形成氢键,主链也有类似的Φ(或者φ,Phi)和Ψ(Psi)角。
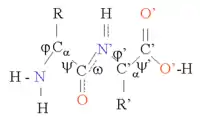
这些结构的形成使每个氨基酸主链的极性得到了中和和稳定。在疏水环境里,二级结构常常紧密地堆叠形成蛋白质核心。每个氨基酸侧链的体积的限制,加之与邻近侧链可能产生的相互作用的限制,我们需要运用分子模拟与结构叠合的手段来预测蛋白质的细微结构[1]。
α螺旋
α螺旋是在蛋白质二级结构中最丰富的类型。α螺旋的平均每个螺旋周期包含3.6个氨基酸,形成一个氢键,在每4个残基中;平均长度为10个氨基酸(3个螺旋)或10埃(Å),但变化范围5到40(Å)(1.5个至11个螺旋)。沿螺旋排列的氢键也构成了带部分电荷的偶极矩,氮端带部分正电。因为氮端有自由的氨基,可以与带负电的基团,比如磷酸基团,进行反应。α螺旋常位于蛋白质核心区靠近表面的位置,有利于于水环境发生作用。面向蛋白内部的螺旋倾向于采用更多的疏水氨基酸,面向外部的多为亲水氨基酸。因此,螺旋链上每四个氨基酸中位置处于的第三位的多为疏水,这也很特征很容易被识别出。比如对亮氨酸拉链模体(Leucine zipper motif)有高度预测性的重复特征是两个相邻的螺旋相对的面上均有亮氨酸的存在。螺旋轮图可以显示出这种重复性的特征。其它的藏在蛋白质核心区或者细胞膜内的α螺旋会更经常分布疏水氨基酸,这样的结构也更能被预测。 暴露在螺旋表面的氨基酸中疏水氨基酸所占的比例会更小。所以说氨基酸的类别组成可以用来预测α螺旋区域。那些有更多丙氨酸(Alanine,A)、谷氨酸(Glutamic acid,E)、亮氨酸(Leucine,L)、蛋氨酸(methionine,M),更少脯氨酸(Proline,P)、甘氨酸(Glycine,G)、酪氨酸(Tyrosine,Y)、丝氨酸 (Serine,S)的氨基酸容易形成α螺旋。脯氨酸通常破坏或者使α螺旋更不稳定,但是在更长可以存在因为它在α螺旋中形成一个弯折。
β折叠
卷曲
一个二级结构的区域不是一个α螺旋,一个β折叠,或可识别的转动,通常被称为一个卷曲(Coils)[1]。
蛋白质分类
参考文献
- Mount DM. 2. Cold Spring Harbor Laboratory Press. 2004. ISBN 0-87969-712-1.
延伸閲讀
- Majorek K, Kozlowski L, Jakalski M, Bujnicki JM. (PDF). Bujnicki J (编). . John Wiley & Sons, Ltd. December 18, 2008: 39–62. ISBN 9780470517673. doi:10.1002/9780470741894.ch2.
- Baker D, Sali A. . Science. October 2001, 294 (5540): 93–6. Bibcode:2001Sci...294...93B. PMID 11588250. doi:10.1126/science.1065659.
- Kelley LA, Sternberg MJ. (PDF). Nature Protocols. 2009, 4 (3): 363–71. PMID 19247286. doi:10.1038/nprot.2009.2. hdl:10044/1/18157.
- Kryshtafovych A, Fidelis K. . Drug Discovery Today. April 2009, 14 (7–8): 386–93. PMC 2808711. PMID 19100336. doi:10.1016/j.drudis.2008.11.010.
- Qu X, Swanson R, Day R, Tsai J. . Current Protein & Peptide Science. June 2009, 10 (3): 270–85. PMID 19519455. doi:10.2174/138920309788452182.
- Daga PR, Patel RY, Doerksen RJ. . Current Topics in Medicinal Chemistry. 2010, 10 (1): 84–94. PMC 5943704. PMID 19929829. doi:10.2174/156802610790232314.
- Fiser, A. . Methods Mol Biol. Methods in Molecular Biology 673. 2010: 73–94. ISBN 978-1-60761-841-6. PMC 4108304. PMID 20835794. doi:10.1007/978-1-60761-842-3_6.
- Cozzetto D, Tramontano A. . Current Protein & Peptide Science. December 2008, 9 (6): 567–77. PMID 19075747. doi:10.2174/138920308786733958.
- Nayeem A, Sitkoff D, Krystek S. . Protein Science. April 2006, 15 (4): 808–24. PMC 2242473. PMID 16600967. doi:10.1110/ps.051892906.
参阅
- 蛋白质设计
- 蛋白质功能预测
- Rosetta@home
外部链接
- (英文)CASP experiments home page
- (英文)ExPASy 蛋白质组学工具 — 预测工具和服务器的列表