UTF-8
UTF-8()是一種針對Unicode的可變長度字元編碼,也是一种前缀码。它可以用一至四个字节对Unicode字符集中的所有有效编码点进行编码,属于Unicode标准的一部分,最初由肯·汤普逊和罗布·派克提出。[2][3]由于较小值的编码点一般使用频率较高,直接使用Unicode编码效率低下,大量浪费内存空间。UTF-8就是为了解决向后兼容ASCII码而设计,Unicode中前128个字符,使用与ASCII码相同的二进制值的单个字节进行编码,而且字面与ASCII码的字面一一对应,這使得原來處理ASCII字元的軟體無須或只須做少部份修改,即可繼續使用。因此,它逐漸成為電子郵件、網頁及其他儲存或傳送文字優先採用的編碼方式。
| 语言 | 國際 |
|---|---|
| 标准 | Unicode |
| 分类 | EASCII 变长编码 Unicode转换格式 |
| 拓展自 | US-ASCII |
| 变换/编码 | ISO 10646 (Unicode) |
| 前用 | UTF-1 |
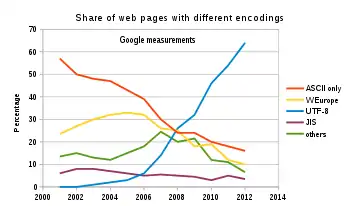
自2009年以来,UTF-8一直是万维网的最主要的编码形式(对所有,而不仅是Unicode范围内的编码)(并由WHATWG宣布为强制性的“适用于所有事物()”,[4]截止到2019年11月, 在所有网页中,UTF-8编码应用率高达94.3%(其中一些仅是ASCII编码,因为它是UTF-8的子集),而在排名最高的1000个网页中占96%。[5] 第二热门的多字节编码方式Shift JIS和GB 2312分别具有0.3%和0.2%的占有率。[6][7][1]Internet邮件联盟()建议所有电子邮件程序都能够使用UTF-8展示和创建邮件,[8] W3C建议UTF-8作为XML文件和HTML文件的默认编码方式。[9]網際網路工程工作小組(IETF)要求所有網際網路協議都必須支持UTF-8編碼[10]。互聯網郵件聯盟(IMC)建議所有電子郵件軟件都支持UTF-8編碼。[11]
歷史
1992年初,為建立良好的位元組串編碼系統以供多位元組字元集使用,開始了一個正式的研究。ISO/IEC 10646的初稿中有一個非必須的附錄,名為UTF。當中包含了一個供32位元的字元使用的位元組串編碼系統。這個編碼方式的性能並不令人滿意,但它提出了將0-127的範圍保留給ASCII以相容舊系統的概念。
1992年7月,X/Open委員會XoJIG開始尋求一個較佳的編碼系統。Unix系統實驗室(USL)的Dave Prosser為此提出了一個編碼系統的建議。它具備可更快速實作的特性,並引入一項新的改進。其中,7位元的ASCII符號只代表原來的意思,所有多位元組序列則會包含第8位元的符號,也就是所謂的最高有效位元。
1992年8月,這個建議由IBMX/Open的代表流傳到一些感興趣的團體。與此同時,貝爾實驗室九號計畫作業系統工作小組的肯·汤普逊對這編碼系統作出重大的修改,讓編碼可以自我同步,使得不必從字串的開首讀取,也能找出字符間的分界。1992年9月2日,肯·汤普逊和羅勃·派克一起在美國新澤西州一架餐車的餐桌墊上描繪出此設計的要點。接下來的日子,Pike及汤普逊將它實現,並將這編碼系統完全應用在九號計畫當中,及後他將有關成果回饋X/Open。
1993年1月25-29日的在聖地牙哥舉行的USENIX會議首次正式介紹UTF-8。
自1996年起,微軟的CAB(MS Cabinet)規格在UTF-8標準正式落實前就明確容許在任何地方使用UTF-8編碼系統。但有關的編碼器實際上從來沒有實作這方面的規格。
结构
UTF-8使用一至六個位元組為每個字符編碼(儘管如此,2003年11月UTF-8被RFC 3629重新規範,只能使用原来Unicode定義的區域,U+0000到U+10FFFF,也就是說最多四個字節):
- 128個US-ASCII字符只需一個位元組編碼(Unicode範圍由U+0000至U+007F)。
- 帶有附加符号的拉丁文、希臘文、西里爾字母、亞美尼亞語、希伯來文、阿拉伯文、敘利亞文及它拿字母則需要兩個位元組編碼(Unicode範圍由U+0080至U+07FF)。
- 其他基本多文種平面(BMP)中的字元(這包含了大部分常用字,如大部分的漢字)使用三個位元組編碼(Unicode範圍由U+0800至U+FFFF)。
- 其他極少使用的Unicode 輔助平面的字元使用四至六位元組編碼(Unicode範圍由U+10000至U+1FFFFF使用四字節,Unicode範圍由U+200000至U+3FFFFFF使用五字節,Unicode範圍由U+4000000至U+7FFFFFFF使用六字節)。
對上述提及的第四種字元而言,UTF-8使用四至六個位元組來編碼似乎太耗費資源了。但UTF-8對所有常用的字元都可以用三個位元組表示,而且它的另一種選擇,UTF-16編碼,對前述的第四種字符同樣需要四個位元組來編碼,所以要決定UTF-8或UTF-16哪種編碼比較有效率,還要視所使用的字元的分佈範圍而定。不過,如果使用一些傳統的壓縮系統,比如DEFLATE,則這些不同編碼系統間的的差異就變得微不足道了。若顧及傳統壓縮算法在壓縮較短文字上的效果不大,可以考慮使用Unicode標準壓縮格式(SCSU)。
描述

目前有好幾份關於UTF-8詳細規格的文件,但這些文件在定義上有些許的不同:
- RFC 3629 / STD 63(2003),這份文件制定了UTF-8是標準的網際網路協議元素
- 第四版,The Unicode Standard,§3.9-§3.10(2003)
- ISO/IEC 10646-1:2000附加文件D(2000)
它們取代了以下那些被淘汰的定義:
- ISO/IEC 10646-1:1993修正案2/附加文件R(1996)
- 第二版,The Unicode Standard,附錄A(1996)
- RFC 2044(1996)
- RFC 2279(1998)
- 第三版,The Unicode Standard,§2.3(2000)及勘誤表#1:UTF-8 Shortest Form(2000)
- Unicode Standard附加文件#27: Unicode 3.1(2001)
事實上,所有定義的基本原理都是相同的,它們之間最主要的不同是支持的字元範圍及無效輸入的處理方法。
Unicode字元的位元被分割為數個部分,並分配到UTF-8的位元組串中較低的位元的位置。在U+0080的以下字元都使用內含其字元的單位元組編碼。這些編碼正好對應7位元的ASCII字符。在其他情況,有可能需要多達4個字元組來表示一個字元。這些多位元組的最高有效位元會設定成1,以防止與7位元的ASCII字符混淆,並保持標準的位元組主導字串運作順利。
| 代碼範圍 十六進制 |
標量值(scalar value) 二進制 |
UTF-8 二進制/十六進制 |
註釋 |
|---|---|---|---|
| 000000 - 00007F 128個代碼 |
00000000 00000000 0zzzzzzz | 0zzzzzzz(00-7F) | ASCII字元範圍,位元組由零開始 |
| 七個z | 七個z | ||
| 000080 - 0007FF 1920個代碼 |
00000000 00000yyy yyzzzzzz | 110yyyyy(C0-DF) 10zzzzzz(80-BF) | 第一個位元組由110開始,接著的位元組由10開始 |
| 三個y;二個y;六個z | 五個y;六個z | ||
| 000800 - 00D7FF 00E000 - 00FFFF 61440個代碼 [Note 1] |
00000000 xxxxyyyy yyzzzzzz | 1110xxxx(E0-EF) 10yyyyyy 10zzzzzz | 第一個位元組由1110開始,接著的位元組由10開始 |
| 四個x;四個y;二個y;六個z | 四個x;六個y;六個z | ||
| 010000 - 10FFFF 1048576個代碼 |
000wwwxx xxxxyyyy yyzzzzzz | 11110www(F0-F7) 10xxxxxx 10yyyyyy 10zzzzzz | 将由11110開始,接著的位元組由10開始 |
| 三個w;二個x;四個x;四個y;二個y;六個z | 三個w;六個x;六個y;六個z |
- Note 1 Unicode在範圍D800-DFFF中不存在任何字元,基本多文種平面中約定了這個範圍用於UTF-16擴展標識辅助平面(兩個UTF-16表示一個辅助平面字符)。當然,任何編碼都是可以被轉換到這個範圍,但在unicode中他們並不代表任何合法的值。
例如,希伯来语字母aleph(א)的Unicode代码是U+05D0,按照以下方法改成UTF-8:
- 它属于U+0080到U+07FF区域,这个表说明它使用双字节,110yyyyy 10zzzzzz.
- 十六进制的0x05D0换算成二进制就是101-1101-0000.
- 这11位数按顺序放入"y"部分和"z"部分:11010111 10010000.
- 最后结果就是双字节,用十六进制写起来就是0xD7 0x90,这就是这个字符aleph(א)的UTF-8编码。
所以开始的128个字元(US-ASCII)只需一字节,接下来的1920个字符需要双字节编码,包括带附加符号的拉丁字母,希腊字母,西里尔字母,科普特语字母,亚美尼亚语字母,希伯来文字母和阿拉伯字母的字元。基本多文種平面中其余的字元使用三个字节,剩余字符使用四个字节。
根据这种方式可以处理更大数量的字元。原来的规范允许长达6字节的序列,可以覆盖到31位元(通用字符集原来的极限)。尽管如此,2003年11月UTF-8被RFC 3629重新规范,能使用原来Unicode定义的区域,U+0000到U+10FFFF。根据这些规范,以下字节值将无法出现在合法UTF-8序列中:
| 编码(二进制) | 编码(十六进制) | 注释 |
|---|---|---|
| 1100000x | C0, C1 | 过长编码:双字节序列的头字节,但码点 <= 127 |
| 1111111x | FE, FF | 无法达到:7或8字节序列的头字节 |
| 111110xx 1111110x |
F8, F9, FA, FB, FC, FD | 被RFC 3629规范:5或6字节序列的头字节 |
| 11110101 1111011x |
F5, F6, F7 | 被RFC 3629规范:码点超过10FFFF的头字节 |
UTF-8编码字节含义
- 对于UTF-8编码中的任意字节B,如果B的第一位为0,则B独立的表示一个字符(ASCII码);
- 如果B的第一位为1,第二位为0,则B为一个多字节字符中的一个字节(非ASCII字符);
- 如果B的前两位为1,第三位为0,则B为两个字节表示的字符中的第一个字节;
- 如果B的前三位为1,第四位为0,则B为三个字节表示的字符中的第一个字节;
- 如果B的前四位为1,第五位为0,则B为四个字节表示的字符中的第一个字节;
因此,对UTF-8编码中的任意字节,根据第一位,可判断是否为ASCII字符;根据前二位,可判断该字节是否为一个字符编码的第一个字节;根据前四位(如果前两位均为1),可确定该字节为字符编码的第一个字节,并且可判断对应的字符由几个字节表示;根据前五位(如果前四位为1),可判断编码是否有错误或数据传输过程中是否有错误。
設計UTF-8的理由
UTF-8的設計有以下的多字元組序列的特質:
- 單位元組字符的最高有效位元永遠為0。
- 多位元組序列中的首個字元組的幾個最高有效位元決定了序列的長度。最高有效位為
110的是2位元組序列,而1110的是三位元組序列,如此類推。 - 多位元組序列中其餘的位元組中的首兩個最高有效位元為
10。
UTF-8的這些特質,保證了一個字符的字节序列不会包含在另一個字符的字节序列中。這確保了以位元組為基礎的部份字串比對(sub-string match)方法可以適用於在文字中搜尋字或詞。有些比較舊的可變長度8位元編碼(如Shift JIS)沒有這個特質,故字串比對的算法變得相當複雜。雖然這增加了UTF-8編碼的字串的信息冗餘,但是利多於弊。另外,資料壓縮並非Unicode的目的,所以不可混為一談。即使在傳送過程中有部份位元組因錯誤或干擾而完全遺失,還是有可能在下一個字符的起點重新同步,令受損範圍受到限制。
另一方面,由於其位元組序列設計,如果一個疑似為字符串的序列被驗證為UTF-8編碼,那麼我們可以有把握地說它是UTF-8字符串。一段兩位元組隨機序列碰巧為合法的UTF-8而非ASCII的機率為32分1。對於三位元組序列的機率為256分1,對更長的序列的機率就更低了。
UTF-8的編碼方式
UTF-8是UNICODE的一種變長度的編碼表達方式一般UNICODE為雙位元組(指UCS2),它由肯·汤普逊()于1992年建立,現在已經標準化為RFC 3629。UTF-8就是以8位为单元对UCS进行编码,而UTF-8不使用大尾序和小尾序的形式,每個使用UTF-8儲存的字符,除了第一個字節外,其餘字節的頭兩個位元都是以"10"開始,使文字處理器能夠較快地找出每個字符的開始位置。
但為了與以前的ASCII碼相容(ASCII為一個位元組),因此UTF-8選擇了使用可變長度字節來儲存Unicode:
(注意:不论是Unicode (Table 3.7) [12],还是ISO 10646 (10.2 UTF-8) [13],目前都只规定了最高码位是0x10FFFF的字元的编码。下表中表示大于0x10FFFF的UTF-8编码是不符合标准的。)
| 码点的位数 | 码点起值 | 码点终值 | 字节序列 | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
|---|---|---|---|---|---|---|---|---|---|
| 7 | U+0000 | U+007F | 1 | 0xxxxxxx | |||||
| 11 | U+0080 | U+07FF | 2 | 110xxxxx | 10xxxxxx | ||||
| 16 | U+0800 | U+FFFF | 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 21 | U+10000 | U+1FFFFF | 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 26 | U+200000 | U+3FFFFFF | 5 | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 31 | U+4000000 | U+7FFFFFFF | 6 | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
- 在ASCII碼的範圍,用一個位元組表示,超出ASCII碼的範圍就用位元組表示,這就形成了我們上面看到的UTF-8的表示方法,這様的好處是當UNICODE文件中有ASCII碼時,儲存的文件都為一個位元組,所以就是普通的ASCII文件無異,讀取的時候也是如此,所以能與以前的ASCII文件相容。
- 大於ASCII碼的,就會由上面的第一位元組的前幾位表示該unicode字元的長度,比如110xxxxx前三位的二進位表示告訴我們這是個2BYTE的UNICODE字元;1110xxxx是個三位的UNICODE字元,依此類推;xxx的位置由字符編碼數的二進製表示的位填入。越靠右的x具有越少的特殊意義。只用最短的那個足夠表達一個字符編碼數的多字節串。注意在多字節串中,第一個字節的開頭"1"的數目就是整個串中字節的數目。
ASCII字母繼續使用1字節儲存,重音文字、希臘字母或西里爾字母等使用2字節來儲存,而常用的漢字就要使用3字節。辅助平面字元則使用4字節。
在UTF-8+BOM格式文件的開首,很多時都放置一個U+FEFF字符(UTF-8以EF,BB,BF代表),以顯示這個文字檔案是以UTF-8編碼。
UTF-8的特性
| UTF-8 | |
|---|---|
| 最小码位 | 0000 |
| 最大码位 | 10FFFF |
| 每字节所占位数 | 8 bits |
| Byte order | N/A |
| 每个字符最小字节数 | 1 |
| 每个字符最大字节数 | 4 |
- UCS字符U+0000到U+007F(ASCII)被編碼為字節0x00到0x7F(ASCII兼容),這也意味著只包含7位ASCII字符的文件在ASCII和UTF-8兩種編碼方式下是一樣的。
- 所有>U+007F的UCS字符被編碼為一個多個字節的串,每個字節都有標記位集。因此,ASCII字節(0x00-0x7F)不可能作為任何其他字符的一部分。
- 表示非ASCII字符的多字節串的第一個字節總是在0xC0到0xFD的範圍裡,並指出這個字符包含多少個字節。多字節串的其餘字節都在0x80到0xBF範圍裡,這使得重新同步非常容易,並使編碼無國界,且很少受丟失字節的影響。
- 可以編入所有可能的231個UCS代碼
- UTF-8編碼字符理論上可以最多到6個字節長,然而16位BMP字符最多只用到3字節長。
- Bigendian UCS-4字節串的排列順序是預定的。
- 字節0xFE和0xFF在UTF-8編碼中從未用到,同時,UTF-8以位元組為編碼單元,它的位元組順序在所有系統中都是一様的,没有位元組序的問題,也因此它實際上并不需要BOM。
- 與UTF-16或其他Unicode編碼相比,對於不支持Unicode和XML的系統,UTF-8更不容易造成問題。
UTF-8編碼的優點
总体来说,在Unicode字符串中不可能由码点数量决定显示它所需要的长度,或者显示字符串之后在文本缓冲区中光标应该放置的位置;组合字符、变宽字体、不可打印字符和从右至左的文字都是其归因。
所以尽管在UTF-8字符串中字元数量与码点数量的关系比UTF-32更为复杂,在实际中很少会遇到有不同的情形。
更詳細的說,UTF-8編碼具有以下幾點優點:
- ASCII是UTF-8的一个子集。因为一个纯ASCII字符串也是一个合法的UTF-8字符串,所以现存的ASCII文本不需要转换。为传统的扩展ASCII字符集设计的软件通常可以不经修改或很少修改就能与UTF-8一起使用。
- 使用标准的面向字节的排序例程对UTF-8排序将产生与基于Unicode代码点排序相同的结果。(尽管这有有限的有用性,因为在任何特定语言或文化下都不太可能有仍可接受的文字排列顺序。)
- UTF-8和UTF-16都是可扩展标记语言文档的标准编码。所有其它编码都必须通过显式或文本声明来指定。页面存档备份,存于
- 任何面向字节的字符串搜索算法都可以用于UTF-8的数据(要输入仅由完整的UTF-8字符组成)。但是,对于包含字符记数的正则表达式或其它结构必须小心。
- UTF-8字符串可以由一个简单的算法可靠地识别出来。就是,一个字符串在任何其它编码中表现为合法的UTF-8的可能性很低,并随字符串长度增长而减小。举例说,字元值C0,C1,F5至FF从来没有出现。为了更好的可靠性,可以使用正则表达式来统计非法过长和替代值(可以查看W3 FAQ: Multilingual Forms上的验证UTF-8字符串的正则表达式)。
- 與UCS-2的比較:ASCII轉换成UCS-2,在編碼前插入一個0x0。用這些編碼,會含括一些控制符,比如"或 '/',這在UNIX和一些C函數中,將會產生嚴重錯誤。因此可以肯定,UCS-2不適合作為Unicode的外部編碼,也因此誕生了UTF-8。
UTF-8編碼的缺點
編寫不良的解析器
一份写得很差(并且与当前标准的版本不兼容)的UTF-8解析器可能会接受一些不同的伪UTF-8表示并将它们转换到相同的Unicode输出上。这为设计用于处理八位表示的校验例程提供了一种遗漏信息的方式。
不利于正则表达式检索
正则表达式可以进行很多英文高级的模糊检索。例如,[a-h]表示a到h间所有字母。
同样GBK编码的中文也可以这样利用正则表达式,比如在只知道一个字的读音而不知道怎么写的情况下,也可用正则表达式检索,因为GBK编码是按读音排序的。但是UTF-8不是按读音排序的,所以不利于用正则表达式检索(虽然正则表达式检索並未考慮中文中的多音字,但是由于中文的多音字数量不多,不少多音字还是同音不同调类型的多音字,所以大多数情况下正则表达式检索是可以接受的)。但是,Unicode是按部首排序的,因此在只知道一個字的部首而不知道如何發音的情况下,UTF-8可用正则表达式检索而GBK不行。
其他
與其他Unicode編碼相比,特別是UTF-16,在UTF-8中ASCII字元佔用的空間有一半,可是在一些字元的UTF-8編碼佔用的空間就要多出1/3,特別是中文、日文和韓文(CJK)這樣的方塊文字。
UTF-8的衍生物
Windows
雖然不是標準,但許多Windows程序(包括Windows记事本)在UTF-8編碼的檔案的開首加入一段位元組串EF BB BF。這是位元組順序記號U+FEFF的UTF-8編碼結果。對於沒有預期要處理UTF-8的文字編輯器和瀏覽器會顯示成ISO-8859-1字符串。
Posix系统
Posix系统明确不建议使用字节序掩码EF BB BF。[14]因为很多文本文件期望以 “#!”(Shebang)开头指示要运行的程序。Linux系统选择使用Unicode规范形式Normalization Form C(NFC),即优先使用预组装字符(precomposed character)而非组合字符序列(combining character sequence)。
2002年9月发布的Red Hat Linux 8.0才开始正式把大多数区域设置的默认编码设为UTF-8。此前是各种语言的但字节编码为主。2004年9月SuSE Linux 9.1开始,缺省编码迁移为UTF-8。
字符串处理时,使用UTF-8或locale依赖的多字节编码情形,比使用C语言wchar_t的宽字符固定宽度编码,要慢1至2个数量级。[14]
Java
在通常用法下,Java程序语言在通过InputStreamReader和OutputStreamWriter读取和写入串的时候支持标准UTF-8。但是,Java也支持一种非标准的变体UTF-8,供对象的序列化,Java本地界面和在class文件中的嵌入常数時使用的modified UTF-8。
變種UTF-8
标准和變種的UTF-8有两个不同点。第一,空字符(null character,U+0000)使用雙字节的0xc0 0x80,而不是单字节的0x00。这保证了在已编码字串中没有嵌入空字节。因为C语言等语言程序中,单字节空字符是用来标志字串结尾的。当已编码字串放到这样的语言中處理,一个嵌入的空字符将把字串一刀两断。
第二个不同点是基本多文種平面之外字符的编码的方法。在标准UTF-8中,这些字符使用4字节形式编码,而在修正的UTF-8中,这些字符和UTF-16一样首先表示为代理对(surrogate pairs),然后再像CESU-8那样按照代理对分别编码。这样修正的原因更是微妙。Java中的字符为16位长,因此一些Unicode字符需要两个Java字符来表示。语言的这个性质蓋過了Unicode的增补平面的要求。尽管如此,為了要保持良好的向后兼容、要改變也不容易了。这个修正的编码系統保证了一个已编码字串可以一次编为一个UTF-16码,而不是一次一个Unicode码点。不幸的是,这也意味着UTF-8中需要4字节的字符在變種UTF-8中变成需要6字节。
因为變種UTF-8并不是UTF-8,所以用户在交换信息和使用互联网的时候需要特别注意不要误把變種UTF-8當成UTF-8数据。
Mac OS X
Mac OS X操作系统使用正式分解万国码(canonically decomposed Unicode),在文件系统中使用UTF-8编码进行文件命名,這做法通常被称为UTF-8-MAC。正式分解万国码中,预组合字符是被禁止使用的,必须以组合字符取代。
这种方法使分类变得非常简单,但是会搞混那些使用预组合字符为标准、组合字符用来显示特殊字符的软件。Mac系统的这种NFD数据是万国码规范化(Unicode normalization)的一种格式。而其他系统,包括Windows和Linux,使用万国码规范的NFC形式,也是W3C标准使用的形式。所以通常NFD数据必须转换成NFC才能被其他平台或者网络使用。
苹果开发者专区有关于此问题的讨论:Apple Q&A 1173。
MySQL
MySQL字符编码集中有两套UTF-8编码实现:“utf8”和“utf8mb4”,其中“utf8”是一个字最多占据3字节空间的编码实现;而“utf8mb4”则是一个字最多占据4字节空间的编码实现,也就是UTF-8的完整实现。这是由于MySQL在4.1版本开始支持UTF-8编码(当时参考UTF-8草案版本为RFC 2279)时,为2003年,并且在同年9月限制了其实现的UTF-8编码的空间占用最多为3字节,而UTF-8正式形成标准化文档(RFC 3629)是其之后。限制UTF-8编码实现的编码空间占用一般被认为是考虑到数据库文件设计的兼容性和读取最优化,但实际上并没有达到目的,而且在UTF-8编码开始出现需要存入非基本多文种平面的Unicode字符(例如emoji字符)时导致无法存入(由于3字节的实现只能存入基本多文种平面内的字符)。直到2010年在5.5版本推出“utf8mb4”来代替、“utf8”重命名为“utf8mb3”并调整“utf8”为“utf8mb3”的别名,并不建议使用旧“utf8”编码,以此修正遗留问题。[15][16][17][18]
参见
参考文献
- Davis, Mark. . Official Google Blog. 2012-02-03 [2019-11-23].
- Pike, Rob. . 2003-4-30 [2019-11-23]. (原始内容存档于2006-10-29).
...UTF-8 was designed, in front of my eyes, on a placemat in a New Jersey diner one night in September or so 1992...So that night Ken wrote packing and unpacking code and I started tearing into the C and graphics libraries. The next day all the code was done...
. - Pike, Rob; Thompson, Ken. (PDF). . 1993 [2019-11-23]. (原始内容存档 (PDF)于2017-10-11).
- . encoding.spec.whatwg.org. [2019-11-23]. (原始内容存档于2015-02-04) (英语).
The problems outlined here go away when exclusively using UTF-8, which is one of the many reasons that is now the mandatory encoding for all things.
- . w3techs.com. [2019-11-23] (英语).
- . [2019-11-14].
- . BuiltWith. [2011-03-28].
- . Internet Mail Consortium. 1998-08-01 [2007-11-08]. (原始内容存档于2007-10-26).
- , , World Wide Web Consortium, 14 December 2017 [2018-06-03]
- 參考RFC 2277 section 3.1
- . 2007-10-26 [2018-07-27].
- (PDF).
- .
- . [2005-06-16]. (原始内容存档于2018-09-24).
- . dev.mysql.com. [2020-04-03].
- . dev.mysql.com. [2020-04-03].
- . dev.mysql.com. [2020-04-03].
- Hooper, Adam. . Medium. 2019-08-19 [2020-04-03] (英语).
外部連結
- RFC 3629:UTF-8標準
- RFC 2277:IETF policy on character sets and languages
- Rob Pike tells the story of UTF-8's creation页面存档备份,存于
- Original UTF-8 paper
- UTF-8 test pages by University Hannover and the World Wide Web Consortium
- Unix/Linux: UTF-8和Unicode的常見問題集页面存档备份,存于,Linux Unicode HOWTO,UTF-8 and Gentoo
- The Unicode/UTF-8-character table displays UTF-8 in a variety of formats(with Unicode and HTML encoding information)
- Online Tool for URL encoding/decoding according to RFC 3986 and RFC 3629(JavaScript,GPL)
- UTF-8測試頁
- UTF-8
由統一碼聯盟出版的書
- The Unicode Standard, Version 5.0, Fifth Edition, The Unicode Consortium, Addison-Wesley Professional,2006年10月27日。ISBN 0-321-48091-0
- The Unicode Standard, Version 4.0, The Unicode Consortium, Addison-Wesley Professional,2003年8月27日。ISBN 0-321-18578-1
