核酸序列
核酸序列(英語:,亦称为核酸的一级结构)是指使用一串字母表示的真实的或者假设的携带基因信息的DNA分子的一级结构。每个字母代表一种核鹼基,两个碱基形成一个碱基对,碱基对的配对规律是固定的,即A =(配对) T,C = G。三个相邻的碱基对形成一个密码子。一种密码子对应一种氨基酸,不同的氨基酸合成不同的蛋白质。在DNA的复制及蛋白质的合成过程中,碱基配对规律是十分关键的。

可能的字母只有A、C、G和T,分别代表组成DNA的四种核苷酸-腺嘌呤,胞嘧啶,鸟嘌呤,胸腺嘧啶。典型的他们无间隔的排列在一起,例如序列AAAGTCTGAC。任意长度大于4的一串核苷酸被称作一个序列。 关于它的生物功能,则依赖于上下文的序列,一个序列可能被正读,反读;包含编码或者无编码。DNA序列也可能包含非編碼DNA。
核苷酸
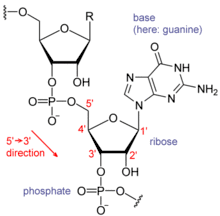
核酸由称为核苷酸的连接单位的长链组成。 每个核苷酸由三个亚基组成:磷酸基团和糖(在RNA的情况下是核糖,而在DNA中的脱氧核糖)构成核酸链的骨架,并且与糖连接是一组核碱基之一。 核碱基在链的碱基对中是重要的,以形成更高级的二级结构和三级结构,例如着名的双螺旋。
可能的字母是A,C,G和T,代表DNA链的四个核苷酸碱基 - 腺嘌呤,胞嘧啶,鸟嘌呤,胸腺嘧啶 - 与磷酸二酯骨架共价连接。 在典型情况下,序列无间隙地相互邻接被印刷,如AAAGTCTGAC序列中从5'到3'方向从左到右读。 关于转录,如果序列与转录的RNA具有相同的顺序,则序列位于编码链上。
一个序列可以与另一个序列互补性(分子生物学),这意味着它们在互补的每个位置上具有碱基(即A至T,C至G)并且以相反的顺序。 例如,TTAC的互补序列是GTAA。 如果双链DNA的一条链被认为是有义链(sense strand),那么被认为是反义链的另一条链将具有与有义链的互补序列。
符号
比较和确定两个核苷酸序列之间的%差异。
- AATCCGCTAG
- AAACCCTTAG
- 给定两个10个核苷酸的序列,将它们排成一行并比较它们之间的差异。 通过将不同DNA碱基的数量除以核苷酸的总数来计算相似性百分比。 在上述情况下,10个核苷酸序列存在三个差异。 因此,将7/10除以得到70%的相似度,并从100%减去得到30%的差异。
虽然A,T,C和G代表某个位置的特定核苷酸,但也有代表模糊性的字母,当在该位置可能出现一种以上的核苷酸时使用这些字母。 国际纯粹与应用化学联合会(IUPAC)的规则如下[1]:
| 符号[2] | 描述 | 被表现碱基 | 互补碱基 | ||||
|---|---|---|---|---|---|---|---|
| A | 腺嘌呤 | A | 1 | T | |||
| C | 胞嘧啶 | C | G | ||||
| G | 鸟嘌呤 | G | C | ||||
| T | 胸腺嘧啶 | T | A | ||||
| U | 尿嘧啶 | U | A | ||||
| W | Weak | A | T | 2 | W | ||
| S | Strong | C | G | S | |||
| M | 胺 | A | C | K | |||
| K | 酮 | G | T | M | |||
| R | 嘌呤 | A | G | Y | |||
| Y | 嘧啶 | C | T | R | |||
| B | 除A外 (B comes after A) | C | G | T | 3 | V | |
| D | 除C外 (D comes after C) | A | G | T | H | ||
| H | 除G外 (H comes after G) | A | C | T | D | ||
| V | 除T外 (V comes after T and U) | A | C | G | B | ||
| N | 任何 Nucleotide (not a gap) | A | C | G | T | 4 | N |
| Z | 0 | 0 | Z | ||||
这些符号对RNA也有效,除了用U(尿嘧啶)代替T(胸腺嘧啶)[1]。
除了腺嘌呤(A),胞嘧啶(C),鸟嘌呤(G),胸腺嘧啶(T)和尿嘧啶(U)之外,DNA和RNA还含有在核酸链形成后已被修饰的碱基。 在DNA中,最常见的修饰碱是5-甲基胞苷(m5C)。 在RNA中,有许多修饰的碱基,包括假尿苷(Ψ),二氢尿苷(D),肌苷(I),核糖胸苷(rT)和7-甲基鸟苷(m7G)[3][4]。 次黄嘌呤和黄嘌呤是通过诱变剂存在产生的许多碱中的两种,它们都通过脱氨作用(用羰基取代胺基)。 次黄嘌呤是由腺嘌呤产生的,而黄嘌呤是由鸟嘌呤产生的[5] 。 类似地,胞嘧啶的脱氨基作用导致尿嘧啶。
生物学意义

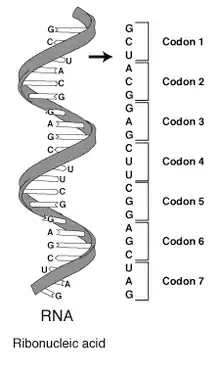
在生物系统中,核酸含有活细胞用于构建特定蛋白质的信息。 核酸链上的核碱基序列通过细胞机器翻译成构成蛋白质链的氨基酸序列。 被称为一个密码子(codon)的每组三个碱基对应于单个氨基酸,并且存在特定的遗传密码,通过该遗传密码,三个碱基的每种可能组合对应于特定氨基酸。
分子生物学的中心法则概述了使用核酸中包含的信息构建蛋白质的机制。 DNA被转录成mRNA分子,其进入核糖体,其中mRNA用作构建蛋白质链的模板。 由于核酸可以与具有互补序列的分子结合,因此在编码蛋白质的“有义”序列和本身无功能但可以与有义链结合的互补“反义”序列之间存在区别。
参考文献
- Nomenclature for Incompletely Specified Bases in Nucleic Acid Sequences, NC-IUB, 1984.
- Nomenclature Committee of the International Union of Biochemistry (NC-IUB). . 1984 [2008-02-04].
- . mun.ca.
- . uw.edu.pl.
- Nguyen, T; Brunson, D; Crespi, C L; Penman, B W; Wishnok, J S; Tannenbaum, S R. . Proc Natl Acad Sci U S A. April 1992, 89 (7): 3030–3034. PMC 48797. PMID 1557408. doi:10.1073/pnas.89.7.3030.