循环神经网络
循环神经网络(Recurrent neural network:RNN)是神經網絡的一種。单纯的RNN因为无法处理随着递归,权重指数级爆炸或梯度消失问题,难以捕捉长期时间关联;而结合不同的LSTM可以很好解决这个问题。[1][2]
| 机器学习与資料探勘 |
|---|
 |
时间循环神经网络可以描述动态时间行为,因为和前馈神经网络(feedforward neural network)接受较特定结构的输入不同,RNN将状态在自身网络中循环传递,因此可以接受更广泛的时间序列结构输入。手写识别是最早成功利用RNN的研究结果。[3]
历史
递归神经网络是基于大卫·鲁梅尔哈特1986年的工作[4]。1982年,约翰·霍普菲尔德发现了Hopfield神经网络——一种特殊的RNN。1993年,一个神经历史压缩器系统解决了一个“非常深度学习”的任务,这个任务在RNN展开之后有1000多个后续层[5]。
LSTM
Hochreiter和Schmidhuber于1997年提出了长短期记忆(LSTM)网络,并在多个应用领域创造了精确度记录[6]。
大约在2007年,LSTM开始革新语音识别领域,在某些语音应用中胜过传统模型[7]。2009年,一个由 CTC 训练的LSTM网络赢得了多项连笔手写识别竞赛,成为第一个赢得模式识别竞赛的RNN。[8][9]2014年,百度在不使用任何传统语音处理方法的情况下,使用经过CTC训练的RNNs打破了Switchboard Hub5'00 语音识别基准。[10]
LSTM还改进了大词汇量语音识别[11][12]和文本到语音合成[13]并在谷歌安卓系统中使用[8][14]。据报道,2015年,谷歌语音识别通过接受过CTC训练的LSTM(谷歌语音搜索使用的)实现了49%的引用量的大幅提升。[15]
LSTM打破了改进机器翻译[16]、语言建模[17]和多语言处理的记录[18]。 LSTM 结合卷积神经网络改进了图像自动标注 。[19]
循环神经网络
编码器
循环神经网络将输入序列编码为一个固定长度的隐藏状态,这里有(用自然语言处理作为例子):


- 是输入序列,比如编码为数字的一系列词语,整个序列就是完整的句子。
- 是随时间更新的隐藏状态。当新的词语输入到方程中,之前的状态就转换为和当前输入相关的,距离当前时间越长,越早输入的序列,在更新后的状态中所占权重越小,从而表现出时间相关性。[20]





其中,计算隐藏状态的方程是一个非线性方程,可以是简单的Logistic方程(tanh),也可以是复杂的LSTM单元(Long Short-Term Memory)。[20] [21] 而有了隐藏状态序列,就可以对下一个出现的词语进行预测:

- ,其中是第t个位置上的输出,它的概率基于之前输出的所有词语。
- 以上概率可以通过隐藏状态来计算:,是所有隐藏状态的编码,总含了所有隐藏状态,比如可以是简单的最终隐藏状态,也可以是非线性方程的输出。因为隐藏状态t就编码了第t个输入前全部的输入信息,也迭代式地隐含了之前的全部输出信息,所以这个概率计算方法是合理的。





这里的非线性方程可以是一个复杂的前馈神经网络,也可以是简单的非线性方程(但有可能因此无法适应复杂的条件而得不到任何有用结果)。给出的概率可以用监督学习的方法优化内部参数来给出翻译,也可以训练后用来给可能的备选词语,用计算其第j个备选词出现在下一位置的概率,给它们排序。排序后用于其它翻译系统,可以提升翻译质量。








结构递归神经网络
结构递归(Recursive)神经网络是一类用结构递归的方式构建的网络,比如说递归自编码机(Recursive Autoencoder),在自然语言处理的神经网络分析方法中用于解析语句。[25] [26]
架构
RNN 有很多不同的变种
完全循环
基本的 RNN 是由人工神经元组织成的连续的层的网络。给定层中的每个节点都通过有向(单向)连接连接到下一个连续层中的每个其他节点。每个节点(神经元)都有一个时变的实值激活。每个连接(突触)都有一个可修改的实值权重。节点要么是输入节点(从网络外部接收数据),要么是输出节点(产生结果),要么是隐藏节点(在从输入到输出的过程中修改数据)。
对于离散时间设置中的监督学习,实值输入向量序列到达输入节点,一次一个向量。在任何给定的时间步长,每个非输入单元将其当前激活(结果)计算为与其连接的所有单元的激活的加权和的非线性函数。可以在特定的时间步长为某些输出单元提供主管给定的目标激活。例如,如果输入序列是对应于口语数字的语音信号,则在序列末尾的最终目标输出可以是对该数字进行分类的标签。
在强化学习环境中,没有教师提供目标信号。相反,适应度函数或奖励函数偶尔用于评估RNN的性能,它通过影响输出单元来影响其输入流,输出单元和一个可以影响环境的执行器相连。这可以被用来玩一个游戏,在这个游戏中,进度是用赢得的点数来衡量的。
每个序列产生一个误差,作为所有目标信号与网络计算的相应激活的偏差之和。对于大量序列的训练集,总误差是所有单个序列误差的总和。
Elman 网络和 Jordan 网络
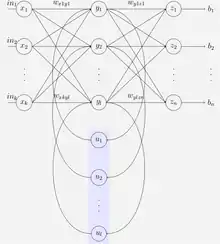
Elman网络是一个三层网络(在图中水平排列为x、y和z),添加了一组上下文单元(在图中为u)。中间(隐藏)层连接到这些权重为1的上下文单元[27]。在每个时间步,输入被向前反馈,并且学习规则被应用。固定的反向连接在上下文单元中保存隐藏单元的先前值的副本(因为它们在应用学习规则之前在连接上传播)。因此,网络可以保持某种状态,允许它执行诸如序列预测之类的任务,这些任务超出了标准多层感知器的能力。
Jordan网络类似于Elman网络。上下文单元是从输出层而不是隐藏层馈送的。Jordan网络中的上下文单元也称为状态层。他们与自己有着经常性的联系。[28]
Elman和Jordan网络也被称为“简单循环网络”。


变量和函数
- : 输入向量
- : 隐藏层向量
- : 输出向量
- , 和 : 参数矩阵和参数向量
- 和 : 激活函数






参考
- 时钟结构的RNN,2014年2月。
- 循环网络结构的经验之谈,谷歌论文,2015年。
- A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, J. Schmidhuber. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 5, 2009.
- Williams, Ronald J.; Hinton, Geoffrey E.; Rumelhart, David E. . Nature. October 1986, 323 (6088): 533–536. Bibcode:1986Natur.323..533R. ISSN 1476-4687. doi:10.1038/323533a0.
- Schmidhuber, Jürgen. (PDF). 1993. Page 150 ff demonstrates credit assignment across the equivalent of 1,200 layers in an unfolded RNN.
- Hochreiter, Sepp; Schmidhuber, Jürgen. . Neural Computation. 1997-11-01, 9 (8): 1735–1780. PMID 9377276. doi:10.1162/neco.1997.9.8.1735.
- Fernández, Santiago; Graves, Alex; Schmidhuber, Jürgen. . Proceedings of the 17th International Conference on Artificial Neural Networks. ICANN'07 (Berlin, Heidelberg: Springer-Verlag). 2007: 220–229. ISBN 978-3-540-74693-5.
- Graves, Alex; Schmidhuber, Jürgen. Bengio, Yoshua; Schuurmans, Dale; Lafferty, John; Williams, Chris editor-K. I.; Culotta, Aron , 编. . Neural Information Processing Systems (NIPS) Foundation: 545–552. 2009.
- Hannun, Awni; Case, Carl; Casper, Jared; Catanzaro, Bryan; Diamos, Greg; Elsen, Erich; Prenger, Ryan; Satheesh, Sanjeev; Sengupta, Shubho. . 2014-12-17. arXiv:1412.5567 [cs.CL].
- Sak, Haşim; Senior, Andrew; Beaufays, Françoise. (PDF). 2014 [2020-02-28]. (原始内容 (PDF)存档于2019-09-22).
- Li, Xiangang; Wu, Xihong. . 2014-10-15. arXiv:1410.4281 [cs.CL].
- Fan, Bo; Wang, Lijuan; Soong, Frank K.; Xie, Lei (2015) "Photo-Real Talking Head with Deep Bidirectional LSTM", in Proceedings of ICASSP 2015
- Zen, Heiga; Sak, Haşim. (PDF). Google.com. ICASSP: 4470–4474. 2015.
- Sak, Haşim; Senior, Andrew; Rao, Kanishka; Beaufays, Françoise; Schalkwyk, Johan. . September 2015.
- Sutskever, Ilya; Vinyals, Oriol; Le, Quoc V. (PDF). Electronic Proceedings of the Neural Information Processing Systems Conference. 2014, 27: 5346. Bibcode:2014arXiv1409.3215S. arXiv:1409.3215.
- Jozefowicz, Rafal; Vinyals, Oriol; Schuster, Mike; Shazeer, Noam; Wu, Yonghui. . 2016-02-07. arXiv:1602.02410 [cs.CL].
- Gillick, Dan; Brunk, Cliff; Vinyals, Oriol; Subramanya, Amarnag. . 2015-11-30. arXiv:1512.00103 [cs.CL].
- Vinyals, Oriol; Toshev, Alexander; Bengio, Samy; Erhan, Dumitru. . 2014-11-17. arXiv:1411.4555 [cs.CV].
- Cho, K., van et al (2014a). 统计机器翻译方法:使用RNN进行短语编码解码。
- 经典模型Long Short-Term Memory的原论文,发表于1997年。
- Bidirectional RNN, (1997)
- Cho. k. et al 使用RNN和对齐模型的短语统计机器翻译方法。(2014.a.)
- 神经网络学习:序列到序列,作者Sutskever,2014年。
- 半监督RAE方法:预测文本情感分布。
- Bilingual Word Embeddings for Phrase-Based Machine Translation. (2014).
- Cruse, Holk; Neural Networks as Cybernetic Systems, 2nd and revised edition
- Elman, Jeffrey L. . Cognitive Science. 1990, 14 (2): 179–211. doi:10.1016/0364-0213(90)90002-E.
- Jordan, Michael I. . Advances in Psychology. Neural-Network Models of Cognition 121. 1997-01-01: 471–495. ISBN 9780444819314. doi:10.1016/s0166-4115(97)80111-2.
