统计学习理论
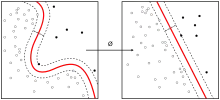
统计学习理论(英語:),一種機器學習的架構,根據統計學與泛函分析(Functional Analysis)而建立。統計學習理論基於資料(data),找出預測性函數,之後解決問題。支持向量机(Support Vector Machine)的理論基礎來自於統計學習理論。
| 机器学习与資料探勘 |
|---|
 |
形式定义
令为所有可能的输入组成的向量空间, 为所有可能的输出组成的向量空间。统计学习理论认为,积空间上存在某个未知的概率分布。训练集由这个概率分布中的个样例构成,并用表示。每个都是训练数据的一个输入向量, 而则是对应的输出向量。








损失函数
损失函数的选择是机器学习算法所选的函数中的决定性因素。 损失函数也影响着算法的收敛速率。损失函数的凸性也十分重要。[1]

根据问题是回归问题还是分类问题,我们可以使用不同的损失函数。





正则化
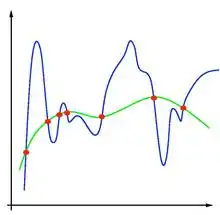
机器学习的一大常见问题是过拟合。由于机器学习是一个预测问题,其目标并不是找到一个与(之前观测到的)数据最拟合的的函数,而是寻找一个能对未来的输入作出最精确预测的函数。经验风险最小化有过拟合的风险:找到的函数完美地匹配现有数据但并不能很好地预测未来的输出。
过拟合的常见表现是不稳定的解:训练数据的一个小的扰动会导致学到的函数的巨大波动。可以证明,如果解的稳定性可以得到保证,那么其可推广性和一致性也同样能得到保证。[2][3] 正则化可以解决过拟合的问题并增加解的稳定性。
正则化可以通过限制假设空间来完成。一个常见的例子是把限制为线性函数:这可以被看成是把问题简化为标准设计的线性回归。也可以被限制为次多项式,指数函数,或L1上的有界函数。对假设空间的限制能防止过拟合的原因是,潜在的函数的形式得到了限制,因此防止了那些能给出任意接近于0的经验风险的复杂函数。


一个正则化的样例是吉洪诺夫正则化,即最小化如下损失函数

其中正则化参数为一个固定的正参数。吉洪诺夫正则化保证了解的存在性、唯一性和稳定性。[4]

- Rosasco, L., Vito, E.D., Caponnetto, A., Fiana, M., and Verri A. 2004. Neural computation Vol 16, pp 1063-1076
- Vapnik, V.N. and Chervonenkis, A.Y. 1971. On the uniform convergence of relative frequencies of events to their probabilities. Theory of Probability and its Applications Vol 16, pp 264-280.
- Mukherjee, S., Niyogi, P. Poggio, T., and Rifkin, R. 2006. Learning theory: stability is sufficient for generalization and necessary and sufficient for consistency of empirical risk minimization. Advances in Computational Mathematics. Vol 25, pp 161-193.
- Tomaso Poggio, Lorenzo Rosasco, et al. Statistical Learning Theory and Applications, 2012, Class 2 页面存档备份,存于
