降维
变量选择
变量选择假定数据中包含大量冗余或无关变量(或称特征、属性、指标等),旨在从原有变量中找出主要变量。现代统计学中对变量选择的研究文献,大多集中于高维回归分析,其中最具代表性的方法包括:
特征提取
特徵提取可以看作变量选择方法的一般化:变量选择假设在原始数据中,变量数目浩繁,但只有少数几个真正起作用;而特征提取则认为在所有变量可能的函数(比如这些变量各种可能的线性组合)中,只有少数几个真正起作用。有代表性的方法包括:
- 主成分分析(PCA)
- 因子分析
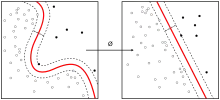
- 核方法(教科书中称为“Kernel method”或“Kernel trick”,常与其他方法如PCA组合使用)
- 基于距离的方法,例如:
- 多维尺度分析
- 非负矩阵分解
- 随机投影法(理论依据是约翰逊-林登斯特劳斯定理)
参见
参考文献
- Roweis, S. T.; Saul, L. K. . Science. 2000, 290 (5500): 2323–2326. PMID 11125150. doi:10.1126/science.290.5500.2323.
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.
