中日韓統一表意文字
中日韓統一表意文字(英語:),也稱統一漢字、統漢碼(英語:),目的是要把分別來自中文、日文、韓文、越南文、壮文、琉球文中,起源相同、本義相同、形狀一樣或稍異的表意文字,在ISO 10646及萬國碼標準賦予相同編碼。
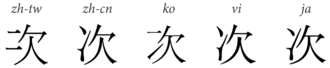 “次”字在繁、簡、韩、越、日汉字标准中的变体 |
|---|
| 汉字字体风格 |
|
陶文 ‧ 甲骨文 ‧ 金文 ‧ 古文 ‧ 石鼓文 |
| 字形 |
|
笔画 ‧ 笔顺 ‧ 偏旁 ‧ 六书 ‧ 部首 右文說 ‧ 同形異義詞 本字 ‧ 石经 ‧ 舊字形新字形 ‧ 通用规范汉字表 國字標準字體 ‧ 常用字字形表 |
| 汉字文化圈 |
|
吴语字 ‧ 粵語字 ‧ 四川方言字 ‧ 南京官話字 舊字體 ‧ 新字体 ‧ 擴張新字體 韩国国语国字问题
吏讀 ‧ 鄉札 ‧ 口訣 |
| 衍生文字 |
|
合文 ‧ 女书 ‧ 则天文字 ‧ 閩南借音字 ‧ 注音符号 |
| 字音 |
|
日本漢字音
古音 ‧ 吳音 ‧ 漢音 ‧ 新漢音 ‧ 宋音 ‧ 唐音 ‧ 慣用音 ‧ 聲調 ‧ 音讀 ‧ 訓讀 ‧ 重箱讀法 ‧ 湯桶讀法 |
| 統一碼 ‧ 中文输入技术 ‧ 中文输入法 |
|
漢字詞 ‧ 錯別字 ‧ ‧ 廢除漢字論 ‧ 漢字復活 ‧ 字謎 |
|
注意:本條目可能有部分無法顯示,若遇此情況請參閱Wikipedia:Unicode擴展漢字。 |
所謂「起源相同、本義相同」、主要是汉字,包括繁體字、簡化字、日本漢字(/)、韓國漢字(/)、琉球汉字(/)、越南的喃字(/)與儒字(/)、方塊壯字(/)。
歷史
1978年,日本基於ISO 2022,制訂了全世界最早的漢字編碼JIS C 6226。1980年代,中國大陸、臺灣、韓國則各自訂了自己的規範。這些規範彼此之間並無關聯。若要在一份文件中同時使用,則要以脫序字符的方式來交換。
1980年,日本的國立國會圖書館的高橋德太郎以圖書學的觀點指出,一個統一的東亞漢字編碼系統是有必要的。同年,臺灣制定了三位元組的中文資訊交換碼。偶然的是,這是第一個期望可以一致處理中國、日本、韓國漢字的編碼。之後,美國的國會圖書館採用了此規格,並另外命名為東亞編碼字符(East Asia Coded Character,EACC,ANSI/NISO Z39.64)。
1984年,ISO的文字編碼委員會(ISO/TC 97/SC2)決議制訂出一套編碼規格(ISO 10646),是以交換文字集的方式來統一處理世界的文字。並成立了工作小組(ISO/TC 97/SC 2/ WG 2)。這個編碼一開始的構想是採用16位元,而對於日本及中國等國的漢字編碼則原封不動地加入。但若如此,中國當時所制訂的編碼都無法加入,因而反對。並於1989年,提出了各國的漢字統合集合(Han Character Collection,HCC)的構想。
1990年完成了ISO 10646的初版草案(DIS 10646)。漢字使用32位元來表示。並將各國的漢字編碼原封不動地加入。但中國認為,若各國各自為漢字編碼,將不利於統一處理漢字,因而反對。為了日後關於漢字編碼的討論及方針能順利進行,並呼籲WG 2特別設置了中日韓聯合研究小組(CJK-JRG,Joint Research Group,為表意文字小組的前身),以持續討論。
另一方面,1987年,全錄的Joe Becker和Lee Collins開發了統合處理全世界所有文字的統一碼。1989年發表了統一碼概要。基本為16位元。於是,中、日、韓文字統合了。基本方針為以16位元處理所有文字。 1990年,完成了基於此方針的最終草案。隔年1991年1月,大致同意此方案的企業成立了統一碼聯盟。中、日、韓中類似的漢字使用約二萬多個字。為了未來擴充,保留了三萬個漢字以供其它用途。
1991年,各國希望能以一致的方式處理文字,如統一碼這般,因而否決了ISO/IEC 10646的初版草案。基於中國與統一碼聯盟的提議,ISO 10646和統一碼成立了中日韓聯合研究小組。中日韓聯合研究小組將基於各國的漢字編碼,獨自訂定規範、制作ISO 10646和統一碼的統一漢字編碼。年尾,完成了Unified Repertoire and Ordering(URO)。
1992年,URO加入ISO 10646的第二版。但是,發現了一些缺失,之後進行了修正。
1993年5月,正式制訂最初的中日韓統一表意文字,位於U+4E00–U+9FFF這個區域,共20,902個字。還有一個漢字“〇”(碼位U+3007),被當成數字放入了符號和標點區。一個月後,制訂了統一碼1.1。
1999年,依據ISO/IEC 10646的第17個修正案(Amendment 17)訂定扩展區A,於U+3400–U+4DFF加入6,582個字。
2001年,依據ISO/IEC 10646-2,新增擴充區B,包含42,711個漢字。位於U+20000–U+2A6FF。但因在短時間內增加了大量的漢字,導致產生了許多重複的字形。
2005年,依據ISO/IEC 10646:2003的第1個修正案(Amendment 1),基本多文種平面增加U+9FA6–U+9FBB,共22個漢字。
2009年,統一碼5.2扩展區C增加U+2A700–U+2B734,基本多文種平面增加U+9FC4–U+9FCB。
2010年,統一碼6.0扩展區D增加U+2B740–U+2B81F。
2012年,統一碼7.0基本多文種平面增加1個漢字:U+9FCC。
2015年,統一碼8.0扩展區E增加U+2B820–U+2CEAF,基本多文種平面增加U+9FCD–U+9FD5。
2017年,统一码10.0扩展區F增加U+2CEB0–U+2EBEF,基本多文種平面增加U+9FD6–U+9FEA。
2018年,統一碼11.0基本多文種平面末尾增加5個漢字:U+9FEB–U+9FEF。
2020年,統一碼13.0增加4,969個漢字,其中4,939個位於第三平面的擴展區G,碼位爲U+30000–U+3134A。同時,亦在基本區增加13字:U+9FF0–U+9FFC,在擴展A區增加10字:U+4DB6–U+4DBF,在擴展B區增加7字:U+2A6D7–U+2A6DD。
另外,第三平面的U+31400–U+33D1F預計放置小篆,U+33E00–U+355FF預計放置甲骨文,相關提案已經提交。按路線圖,該平面還會收錄金文、簡帛文、陶文、鳥蟲書等[1]。
版本
| ISO 10646版本 | Unicode版本 | 新增 | 置放平面 | 字數 | 累計字數 |
|---|---|---|---|---|---|
| 1993 | 1.0 | 中日韓統一表意文字(U+4E00–U+9FA5) | 基本多文種平面 | 20,902 | 20,915 |
| 1個漢字(U+3007,〇),於中日韓符號和標點區 | 基本多文種平面 | 1 | |||
| 位於「相容表意文字區」中但實則獨一的漢字(U+FA0E﨎、U+FA0F﨏、U+FA11﨑、U+FA13﨓、U+FA14﨔、U+FA1F﨟、U+FA21﨡、U+FA23﨣、U+FA24﨤、U+FA27﨧、U+FA28﨨、U+FA29﨩)[註 1] | 基本多文種平面 | 12 | |||
| 2000 | 3.0 | 中日韓統一表意文字擴展區A(U+3400–U+4DB5) | 基本多文種平面 | 6,582 | 27,497 |
| 2001 | 3.1 | 中日韓統一表意文字擴展區B(U+20000–U+2A6D6) | 第二辅助平面 | 42,711 | 70,208 |
| 2003第一修訂版 | 4.1 | HKSCS-2004中未加入ISO 10646的漢字(U+9FA6–U+9FB3,) | 基本多文種平面 | 22 | 70,230 |
| 2003第四修訂版 | 5.1 | 7個日語漢字[3](U+9FBC–U+9FC2,龼龽龾龿鿀鿁鿂),U+4039拆分為U+4039和U+9FC3鿃[4] | 基本多文種平面 | 8 | 70,238 |
| 2003第五修訂版 | 5.2 | 中日韓統一表意文字擴展區C(U+2A700–U+2B734) | 第二辅助平面 | 4,149 | 74,395 |
| 2003第六修訂版 | 2個日語用漢字(ARIB #47、#95,U+9FC4鿄,U+9FC5鿅)、1個新增漢字(ARIB #93,U+9FC6鿆)、在HKSCS-2004推出後新增的5個香港漢字[5](U+9FC7–U+9FCB,鿇鿈鿉鿊鿋) | 基本多文種平面 | 8 | ||
| 2010 | 6.0 | 中日韓統一表意文字擴展區D(U+2B740–U+2B81D) | 第二輔助平面 | 222 | 74,617 |
| 2012 | 6.1 | 1個漢字(U+9FCC鿌) | 基本多文種平面 | 1 | 74,618 |
| 2015 | 8.0 | 中日韓統一表意文字擴展區E(U+2B820–U+2CEA1) | 第二輔助平面 | 5,762 | 80,389 |
| 「急用漢字」:《通用规范汉字表》餘下未收入的3个汉字(U+9FCD–U+9FCF,鿍鿎鿏),1个从U+4CA4(䲤)分离出来的字U+9FD0(鿐),5个其他图书用字及化学元素用字(U+9FD1–U+9FD5,鿑鿒鿓鿔鿕) | 基本多文種平面 | 9 | |||
| 2017 | 10.0 | 中日韓統一表意文字擴展區F(U+2CEB0–U+2EBE0) | 第二輔助平面 | 7,473 | 87,883 |
| 21個漢字(U+9FD6–U+9FEA,鿖鿗鿘鿙鿚鿛鿜鿝鿞鿟鿠鿡鿢鿣鿤鿥鿦鿧鿨鿩鿪) | 基本多文種平面 | 21 | |||
| 2018 | 11.0 | 5個漢字(U+9FEB–U+9FEF,鿫鿬鿭鿮鿯),前三個是新命名的化學元素用字,後兩字來自日本 | 基本多文種平面 | 5 | 87,888 |
| 2020 | 13.0 | 中日韓統一表意文字擴展區G(U+30000–U+3134A) | 第三輔助平面 | 4939 | 92,857 |
| 急用科學與技術用字[6](U+9FF0–U+9FFC,鿰鿱鿲鿳鿴鿵鿶鿷鿸鿹鿺鿻鿼)、10個需分離的漢字[7][8][9](U+4DB6–U+4DBF,䶶䶷䶸䶹䶺䶻䶼䶽䶾䶿) | 基本多文種平面 | 23 | |||
| 崑曲工尺譜用字[10](U+2A6D7–U+2A6DD,𪛗𪛘𪛙𪛚𪛛𪛜𪛝) | 第二辅助平面 | 7 |
成員機構
- Unicode 協會
 中华人民共和国
中华人民共和国 香港(政府資訊科技總監辦公室轄下中文界面諮詢委員會)
香港(政府資訊科技總監辦公室轄下中文界面諮詢委員會) 日本
日本 大韓民國
大韓民國
 澳門(資訊系統中文編碼工作小組,由行政公職局協調)
澳門(資訊系統中文編碼工作小組,由行政公職局協調) 马来西亚(2008年11月第31次IRG會議加入)
马来西亚(2008年11月第31次IRG會議加入) 中華民國(台北市電腦商業同業公會)
中華民國(台北市電腦商業同業公會) 越南
越南 英國 (https://github.com/unicode-org/uk-source-ideographs/ 页面存档备份,存于)
英國 (https://github.com/unicode-org/uk-source-ideographs/ 页面存档备份,存于)- 大藏經文本數據庫委員會(,SAT)
收字來源
最初期統一漢字
最初期的統一漢字共20,902字,其範圍為:U+4E00–U+9FA5。其收字來源包括了以下字集:
| 類別 | 來源代碼 | 名稱 | 字數 |
|---|---|---|---|
| 中國大陸 國標源(G) |
G0 | GB 2312-80 | 6763字 |
| G1 | GB 12345-90 | 2352字(含58個香港字和92個吏讀字,不包括和GB 2312重複的字) | |
| G3 | GB 7589-87 繁體版本 | 7237字 | |
| G5 | GB 7590-87 繁體版本 | 7039字 | |
| G7 | 現代漢語通用字表 | 42字(G0, 1, 3, 5, 8未包括的字) | |
| G8 | GB 8565.2-89 | 290字(G0, 1, 3, 5未包括的字) | |
| 臺灣源(T) | T1 | CNS 11643-1986第一字面 | 5401+9字計量用漢字 |
| T2 | CNS 11643-1986第二字面 | 7650字 | |
| TE | CNS 11643-1986第十四字面 | 6319+239字中文資訊交換碼特字+10個全錄字符集(Xerox Character Code Standard,XCCS)特字 | |
| 日本源(J) | J0 | JIS X 0208-90 | 6335字+非漢字1個(仝)[11] |
| J1 | JIS X 0212-90 | 5801字 | |
| 韓國源(K) | K0 | KS C 5601-87 | 4888字(含268個重見字[12]) |
| K1 | KS C 5657-91 | 2856字 | |
| 委員會源(U) | KS C 5601-1987(當中重複的漢字) | ||
| 美國國會圖書館之東亞字元編碼(East Asia Character Code,簡稱EACC;標準號ANSI Z39.64-1989)[13] | |||
| 大五碼 | |||
| 中文資訊交換碼第一字面 | |||
| GB 12052-89(漢字部分) | |||
| (富士通標準) | |||
| 中國大陸電報碼 | |||
| 臺灣電報碼(CCDC) | |||
| 全錄中文編碼 | |||
| 人名用漢字准用字體表(人名用漢字許容字体表;日本) | |||
| IBM選取的日本和韓國表意文字 |
其中,統一碼技術委員會源(U源)是指,並非由表意文字小組所遞交的參考字集,而是委員會額外遞交作參考的字集標準。並且此來源的字集不適用原字集分離原則(見稍後)。
擴展A區
擴展A區包含有6,582個漢字,位置在U+3400—U+4DB5。這6千多個漢字分別從以下字典或字集中取得:
| 類別 | 來源代碼 | 名稱 | 字數 |
|---|---|---|---|
| 中國大陸 国标源(G) |
G_KX | 《康熙字典》 | 5357字(獨有1892字) |
| G_HZ | 《漢語大字典》 | 5888字(獨有339字) | |
| G3 | GB 7589-87繁体版本 | 2391字 | |
| G5 | GB 7590-87繁体版本 | 1226字 | |
| G7 | 現代漢語通用字表 | 120字 | |
| GS | 新加坡漢字 | 226字 | |
| 臺灣源(T) | T3 | CNS 11643-1992第三字面(原本為CNS 11643-1986第十四字面)新加入字符 | 2178字 |
| T4 | CNS 11643-1992第四字面 | 2917字 | |
| T5 | CNS 11643-1992第五字面 | 395字 | |
| T6 | CNS 11643-1992第六字面 | 197字 | |
| T7 | CNS 11643-1992第七字面 | 133字 | |
| TF | CNS 11643-1992第十五字面 | 86字 | |
| 日本源(J) | JA | 日本資訊科技零售商統一當代表意文字(1993) | 574字 |
| 韓國源(K) | K2 | PKS C 5700-1:1994 | |
| K3 | PKS C 5700-2:1994 | 1834字 | |
| 越南源(V) | V0 | TCVN 5773:1993 | 138字 |
| V1 | TCVN 6056:1995 |
擴展B區
擴展B區包含有42,711個漢字,位置在U+20000—U+2A6D6。根據IRG N777號文件 页面存档备份,存于,這四萬多個漢字分別從以下字典或字集中取得:
| 類別 | 來源代碼 | 名稱 | 字數 |
|---|---|---|---|
| 中國大陸 国标源(G) |
G_KX | 《康熙字典》 | 18486字(包括一個在補遺篇中出現的漢字) |
| G_HZ | 《漢語大字典》 | 28914字 | |
| G_CY | 《辭源》 | 66字 | |
| G_CH | 《辭海》 | 247字 | |
| G_HC | 《漢語大詞典》 | 553字 | |
| G_BK | 《中國大百科全書》 | 86字 | |
| G_FZ | 北大方正排版系统 | 65字 | |
| G_4K | 《四庫全書》 | 522字 | |
| 香港源(H) | H | 香港增補字符集(HKSCS) | 1081字 |
| 臺灣源(T) | T4 | CNS 11643-1992第四字面 | 3408字 |
| T5 | CNS 11643-1992第五字面 | 8111字 | |
| T6 | CNS 11643-1992第六字面 | 5934字 | |
| T7 | CNS 11643-1992第七字面 | 6299字 | |
| TF | CNS 11643-1992第十五字面 | 6401字 | |
| 日本源(J) | J3 | JIS X 0213:2000, level 3 | 25字 |
| J3A | JIS X 0213:2004, level 3 | 1字 | |
| J4 | JIS X 0213:2000, level 4 | 277字 | |
| 韓國源(K) | K4 | PKS 5700-3:1998 | 166字 |
| 朝鮮源(KP) | KP0 | KPS 9566-97 | |
| KP1 | KPS 10721-2000 | 5766字 | |
| 越南源(V) | V2 | VHN 01:1998 | 2290字 |
| V3 | VHN 02:1998 | 425字 |
這些漢字中重複的漢字有不少,所以經過整理之後,實際總數只有42,711個漢字。
另外,在U+2F800—U+2FA1D的位置,放了542個來自臺灣的兼容漢字。
Unicode 4.1漢字
為使Unicode向下兼容GB 18030和香港增補字符集(HKSCS)的所有漢字,而擴展C區又遲遲未能出籠,在Unicode 4.1版中引進了14個香港增補字符集的用字和8個GB 18030用字。該22字被編於U+9FA6–U+9FBB的位置。
另外,在U+FA70—U+FAD9的位置,放了106個來自北韓的兼容漢字。
Unicode 5.1漢字
在2008年4月推出的Unicode 5.1版本,收錄7個由日本Adobe公司遞交的日語漢字(U+9FBC–U+9FC2)[14],和鿃(大字加兩個入字,就如陝西省的字換上目字旁)(U+9FC3)。本來Unicode 3.0收錄了目字旁加(大字加兩個人字)字的「」(U+4039),目字旁加㚒字的字,與「」無論在意義和發音均不相同,故魏安(Andrew West)和井作恆(John H. Jenkins)申請追加此字[15]。
擴展C區
於2009年10月發布的Unicode 5.2涵蓋了擴展C區,共收錄4,149個漢字,包括來自中國大陆、澳門、臺灣、日本、越南等尚未被編碼的漢字。位置在U+2A700—U+2B734。這四千多個漢字分別從以下字典或字集中取得:
| 類別 | 來源代碼 | 名稱 | 字數 |
|---|---|---|---|
| 中國大陸 国标源(G) |
G_BK | 《中國大百科全書》 | 74字 |
| G_FZ | 北京大学方正排版系统 | 1字 | |
| G_HZ | 《漢語大字典》 | 1字 | |
| G_HC | 《漢語大詞典》 | 14字 | |
| G_GH | 《古代漢語詞典》 | 50字 | |
| G_GJZ | 商務印書館用字 | 61字 | |
| G_XC | 《現代漢語詞典》 | 25字 | |
| G_CH | 《辭海》 | 264字 | |
| G_KX | 《康熙字典》及補遺 | 6字 | |
| G_CYY | 中國測繪科學研究院用字 | 55字 | |
| G_ZFY | 《漢語方言大辭典》 | 202字 | |
| G_ZJW | 366字 | ||
| 臺灣源(T) | TC | CNS 11643-1992第12字面 | 634字 |
| TD | CNS 11643-1992第13字面 | 767字 | |
| TE | CNS 11643-1992第14字面 | 350字 | |
| 澳門源 | MAC | 澳門資訊系統字集(Colectânea dos Caracteres Chineses dos Sistemas Informáticos de Macau) | 16字 |
| 日本源(J) | JK | 日本國字集(Japanese KOKUJI Collection) | 367字 |
| 韓國源(K) | K5 | 韓國表意文字小組漢字集第五版(2001,Korean IRG Hanja Character Set 5th Edition: 2001) | 404字(當中主要包含古代字例) |
| 朝鮮源(KP) | KP1 | KPS 10721:2003 | 5357字(獨有1892字) |
| 越南源(V) | V4 | 《喃字詞典》()[阮光紅(),2006] | |
| 《岱喃字字典》(,,2006) | |||
| 《沔南喃字榜查》(,,1994) | |||
| 委員會源(U) | ABC Chinese-English Dictionary(德范克,John DeFrancis等,第二版(1998),火奴魯魯:夏威夷大學出版社) | ||
| 耶穌基督後期聖徒教會香港分會用字 | |||
| Mathews' Chinese-English Dictionary(Robert H. Mathews(1975),劍橋:哈佛大學出版社) | |||
| 宋本《廣韻》 | |||
| 《中國鳥類系統檢索》(鄭作新等,北京:科學出版社,2000) | |||
| 段玉裁《說文解字注》 |
擴展D區
擴展D區包含的都是所謂的「急用漢字」,合共222個新漢字,於2010年下半年發布的Unicode 6.0中,編碼範圍為U+2B740–U+2B81F(實際有字元為U+2B740–U+2B81D)。
擴展D區原本計劃放置擴展C區未收錄的16,000多個漢字,但在2007年5月,臺灣撤消了6,545個第二部分字集內私用漢字,不再使用字,原因是那些人名用字的擁有人或已去世或已移居外地[16],此後擴展D區縮減到大約10,000字左右[17]。由於各種阻礙,協議先把數量較少,又急切要收錄的漢字提交出來,就是「急用漢字」,以便和統一碼6.0.0版一起發表。提出的急用漢字只有二百二十二字(本來有二百二十三字,但日本撤回其中一字)。現在文字小組把第二部分字集延後到擴充E區。
| 類別 | 來源代碼 | 名稱 | 字數 |
|---|---|---|---|
| 中國大陸 国标源(G) |
G_CH | 《辭海》 | 1字 |
| G_IDC | 公安部身份證系統人名和地名用字 | 31字 | |
| G_XC | 《现代汉语词典》 | 4字 | |
| G_ZH | 《中华字海》 | 39字 | |
| 臺灣源(T) | TB | CNS 11643-2007第11平面24字(教育部閩客方言用字) | 24字 |
| 日本源(J) | JH | 通用電子情報交換環境整備計劃(,日本經濟產業省提出的人名和地名用字) | 108字 |
| 委員會源(U) | Adobe-Japan1-5和Adobe-CNS1-5字體裏的異體字 | 15字 |
擴展E區
扩展E区亦在2015年6月17日的Unicode 8.0中发布,放置于编码范围U+2B820–U+2CEAF。
扩展E区本应包含扩展D区未收录的10000多个汉字,但在2008年11月,中国大陆以“难以逐个找证据”为理由,撤销了3215个汉字[18],这些汉字主要用于地名、人名、姓氏,亦有数百个《中国大百科全书》中的文字。这是继台湾撤销6545字之后的又一次大规模撤销。之后又经过长时间的检查处理,E区最终定稿,共有5762字[19]。
这些汉字来源如下:
| 类别 | 来源代码 | 名称 | 字数 |
|---|---|---|---|
| 中國大陸 国标源(G) |
G_BK | 《中国大百科全书》 | 15字 |
| G_CH | 《辞海》 | 112字 | |
| G_CY | 《辞源》 | 3字 | |
| G_CYY | 中国测绘科学院用字(地名用字) | 98字 | |
| G_DZ | 地質出版社用字 | 1字 | |
| G_GH | 《古代汉语词典》 | 176字 | |
| G_HC | 《汉语大词典》 | 7字 | |
| G_IDC | 公安部身份证系统人名和地名用字 | 36字 | |
| G_JZ | 商务印书馆用字 | 147字 | |
| G_KX | 《康熙字典》 | 22字 | |
| G_RM | 人民日報用字 | 3字 | |
| G_WZ | 漢語大詞典出版社用字 | 12字 | |
| G_XC | 《现代汉语词典》 | 57字 | |
| G_XH | 《新華字典》 | 4字 | |
| G_ZFY | 《汉语方言大辞典》 | 712字 | |
| G_ZJW | 1410字 | ||
| 臺灣源(T) | TC | CNS 11643-1992第12平面323字(台湾人名用字) | 323字 |
| TD | CNS 11643-1992第13平面595字(台湾人名用字) | 595字 | |
| TE | CNS 11643-1992第14平面339字(台湾人名用字) | 339字 | |
| 日本源(J) | JK | 日本国字集 | 415字 |
| 澳門源(M) | MAC | 澳門資訊系統字集 | 48字 |
| 委員會源(U) | UTC | 从各处收集到的未收录汉字 | 227字 |
| 越南源(V) | V4 | 《喃字詞典》()[阮光紅(),2006] | 1028字 |
| 《岱喃字字典》(,,2006) | |||
| 《沔南喃字榜查》(,,1994) |
急用漢字
「急用漢字」是擴展E區整理後期,各地新發現並急於使用,又等不及放入擴展F區的字;和擴展E區一起收入Unicode 8.0,位置在U+9FCD–U+9FD5;當中中國大陸在此處申請收入三字,連同擴展E區的字,通用規範漢字表的8105字至此全部收入。
擴展F區
扩展F区在2017年6月20日的Unicode 10.0中发布,编码范围为U+2CEB0–U+2EBEF。
扩展F区来源于新提交的一批汉字,主要包括一千多个方块壮字及数千个佛经、古籍中的用字以及日本户籍用字,共有7473字。
这些汉字的来源如下:
| 类别 | 来源代码 | 名称 | 字数 |
|---|---|---|---|
| 中國大陸 国标源(G) |
G_CY | 《辞源》 | 122字 |
| G_FC | 《现代汉语规范词典》 | 27字 | |
| G_IDC | 公安部身份证用字 | 1字 | |
| G_LGYJ | 《壮族嘹歌研究》 | 1字 | |
| G_OCD | 《牛津英汉汉英词典》 | 2字 | |
| G_PGLG | 《壮族民歌文化丛书·平果嘹歌》 | 70字 | |
| G_XHZ | 《新华大字典》 | 51字 | |
| G_Z | 《古壮字字典》 | 995字 | |
| G_ZJW | 《殷周金文集成引得》 | 33字 | |
| G_ZYS | 《壮族人民的文化遗产——方块壮字》《中国民族古文字研究》 | 2字 | |
| 日本源(J) | JMJ | 日本文字信息基础工程 | 1645字 |
| 韩国源(K) | KC | 韩国历史信息中心 | 1793字 |
| 澳門源(M) | MAC | 澳門資訊系統字集 | 22字 |
| 大藏经研究组(SAT) | USAT | 《大正新修大藏经》 (SAT版) | 2884字 |
| 委員會源(U) | UTC | 从各处收集到的未收录汉字 | 1字 |
擴展G區
於2020年3月10日公佈的Unicode 13.0中在第三輔助平面收錄擴展區G的4,939個漢字,碼位為U+30000–U+3134A[20][21]。
这些汉字的来源如下(部分字符來自多於一個來源,所以下表總數多於收錄總數4,939字):
| 类别 | 来源代码 | 名称 | 字数 |
|---|---|---|---|
| 中國大陸 国标源(G) |
G_HZR | 《汉语大字典》(第二版) | 878字 |
| G_PGLG | 《壮族民歌文化丛书·平果嘹歌》 | 13字 | |
| G_Z | 《古壮字字典》 | 1191字 | |
| 韩国源(K) | KC | 韩国历史信息中心 (한국 역사 정보 통합 시스템) | 428字 |
| 臺灣源(T) | T13 | CNS 11643 第19字面 (將設立的新平面) | 347字 |
| TB | CNS 11643 第11字面 | 3字 | |
| TC | CNS 11643 第12字面 | 2字 | |
| TD | CNS 11643 第13字面 | 1字 | |
| 英國源(UK) | UK | IRG N2107R2 | 1566字 |
| 大藏经研究组(SAT) | USAT | 《大正新修大藏经》 (SAT版) | 329字 |
| 委員會源(U) | UTC | 从各处收集到的未收录汉字 | 239字 |
認同原則與原字集分離原則
表意文字認同原則(Han Unification Rule,又稱表意文字統合原則)與原字集分離原則(Source Separation Rule,又稱來源字集分離原則、原規格分離原則、字源分離原則),是兩個對立的原則,它們是Unicode整理中日韓統一表意文字的基礎。
東亞各國字形多有微妙的差異。如「房」字的第一筆,韓國傳統漢字字形、臺灣教育部標準字體作撇「」;香港教育參考字形、中國大陆規範作點「」;日本標準作橫「」。又如「次」字的左旁,韓國採用傳統字形,首筆爲橫,次筆爲挑;臺灣教育部作兩橫;大陸、日本、香港等則作「冫」(俗稱兩點水)。這種程度的差異,理想上是整併為一個字為佳。否則,要是凡異體字都收進不同碼位裏,Unicode收錄的漢字就會過於臃腫,用戶搜尋時也會因異體問題而找不到想要的結果。
然而,從之前各種受挫之文字整併計劃的經驗得知,整合字集與現行通用字集(Big5或國標碼)等無法一一對應,是推行整合字集的最大阻礙。例如,日本的JIS編碼同時收錄了「」字與「」字,原本JIS文件裏這兩個字可以並存。如果採用整合字集後,它們會變成同一個字,就會造成使用上的困擾。而且,如果將多個不同地區字形合併,會影響閱讀者,令使用者不習慣並非以往所見字形;更有可能引致閱讀者因習慣而書寫不屬於自己地區的字形(或地區性的異體字)。
於是,表意文字認同原則與原字集分離原則就應運而生。
在表意文字認同原則下,Unicode「只對字(Character),而不對字形(Glyph)」編碼,會把同一字的不同字形(即異體字)合併。好像上述的「次」字,在Unicode裏會整併成一個碼。又例如不同地區而有不同寫法的部首,如「(中國大陸規範、日本新字體)、(港臺舊字形、韓國、日本舊字體)、(臺灣教育部)」、「(中國大陸規範、臺灣教育部)、(日本新字體)、(日本舊字體、韓國、港臺舊字形)」、「(中國大陸、港臺新字形)、(舊字形)」等,會合併編碼。這些部首的寫法差異就會交由字型處理。比如說,使用依中國大陸漢字標準《印刷通用漢字字形表》的字體下(如中易宋體、微軟雅黑體)便會出現「、」;使用臺灣教育部標準字體(如微軟正黑體或新版細明體,但非舊版細明體[註 2])就會出現「、」等字形。這大大解決了因地區而異之部首寫法。
至於原字集分離原則是指,在上述所列出之各種收字來源裏,若有任何字集同時收了兩種以上的文字字形,則在Unicode中日韓統一表意文字中,也同時收錄這些字。這樣一來,現行的各種原有字集與Unicode漢字可以一一對應。比如「房」字,各地字集都沒有分別編碼,就只編進一個碼位,部首第一筆的寫法交由字型處理。然而,「」、「」、「」這三個字,在一些地區標準裏是分別編碼的,Unicode則以三個碼位來分別收錄它們。上述的「」與「」也一樣,被安放到不同的碼位中。
基於上述運作,Unicode能大幅減少收錄漢字字數,同時讓地區編碼過渡至Unicode時,字集裏的字元不會有流失。但是,原字集分離原則破壞了Unicode「只對字,而不對字形」編碼之原則,使某些漢字獲得兩個或多個編碼,亦遭受不少批評。
後來的一些重複漢字會使用“兼容区”提供暂存编码,可通过归一化()步骤移除。一般的漢字輸入法,以及多數漢字字型,也不支援兼容區字元。
另外,原字集分離原則只適用於最初Unified Repertoire and Ordering(URO)的20,902字,換言之,由「擴展區A」開始就不再適用。原因是個別地區提交了不少僅有十分輕微差異的字樣,比如台灣《異體字字典》裏的各種異體,要求Unicode分別編碼。然而,那些字樣所建基的地區編碼,並非該地區的通用編碼,例如是中文標準交換碼(台灣實際通行的編碼是Big5碼)。若Unicode全面採納,將會令Unicode對異體字的處理更混亂。
今天,異體字選擇器(Variation Sequence)以及Adobe常用的CID字型等技術,已容許在一個Unicode編碼裏收錄和調用兩個或多個漢字字樣,原字集分離原則在今天已成爲過時技術的副產品。
起源不同原則
留意的是,可以整併的字只限異體字。如果有些漢字,它的音、義根本不一樣,是兩個不相同的字,即使它們外形相近,寫法差異比另一些整併的字少,但仍不能合併。這規則稱爲起源不同原則(Noncognate Rule)。
擧例說:「土」和「士」雖然形似,卻是兩個不同的字,我們不可以整併它們。然而,日本、韓國、大陸、香港等地的「」字,與臺灣教育部的「」字,兩者頂部分別是「土」和「士」,但它們音義全同,是同一字的異體,於是就能夠整併。
其他起源不同的例子還有「」與「」(「月偏旁」與「肉偏旁」對立)、「」與「」(「肉底」與「冃底」對立),「柿」和「杮」(右方「市部件」與「巿部件」對立),「汨」和「汩」(右方「日部件」與「曰部件」對立),「」與「」(右旁「部件」與「部件」對立)等。
然而,漢字中有「同形字」的現象,有兩個或多個讀音與字義,雖然字源不同,卻由同一字形表達出來。比如漢字「芸芸眾生」的「芸」,與日本漢字「藝」字的新字体「芸」,是同形字。要是這些同形字,在字形上確實相同而非相似(「芸」字的草頭雖然有三筆的「」、四筆的「」等不同寫法,但它們都只同一部件,沒有形成對立),就不會應用起源不同原則。
學界批評
中文文字學學界對Unicode的原字集分離原則有不少批評,尤其是它令同一個異體部件時而分離,時而合併,在日常使用層面引伸了許多問題。擧例說,「」和「」、「」和「」都在正常區域中作分離編碼,獲得兩個碼位;「晴」、「靖」、「精」雖也獲兩個碼位,但其中一個是在兼容區中,日常難以應用;「請」、「情」、「蜻」、「靜」更只有一個碼位。或例如,「」和「」、「」和「」是被整併的,可是「」和「」卻分離作兩個碼位。Unicode的做法,沒有把含有相同異體部件的字全都合併,也沒有把它們全都分離,結果經常導致字形不一致,或者使用者無法選擇他希望使用的字形[22]。
其他漢字使用地區也有類似聲音。例如「」和「」兩個偏旁,前者爲「」的大陸簡化字,後者爲「」的日本新字体,在「」和「」、「」和「」、「」和「」等組合裏,就整併起來。可是碰到「」和「」,卻不統合,分列U+685F與U+6808兩個碼位中。這種情況被日本學者指爲Unicode的矛盾[23]。
事實上,由於在「中日韓統一表意文字」的不同區域裏,Unicode本身也使用了不一致的併分尺度,因此,早期的異體字時常獲分配正常碼位,後來常常只有兼容區的暫存編碼,再後來則不時被直接整併並交由異體字選擇器處理。若不修正或更改早期的編碼,類似的問題將會持續存在。
批評
收字過少
合併異體字,雖有助減少收錄字數,但在研究學術時,如古籍、歷史及文字研究等,部份文獻確要將字形不同之字同時並列。已合併的各個字,在這些文獻裏變得各有各意思。學者若使用Unicode,遇到這種情況,就要用不同電腦字型去顯示同一個字碼,甚至要自行造字,或捨Unicode而用其他編碼。一來尋找、轉換電腦字型構成不便,二來有損Unicode記錄每一個字之用意,三來不能以純文本交換,四來電腦字型或因授權條款之限,難以交換流傳。另外,這亦等於不能以Unicode準確記錄文獻,不利於文本的電腦化。
不同字形之字合併後,若檢索方法以字形爲本,會產生混亂,難以檢索。例如筆畫檢字,艸部之「頭」,中國、日本算作三畫,而傳統中文爲四畫,留有「」形者則爲六畫。Unicode同一字碼,源於字形不同,就有幾種筆畫,檢索混亂。即使檢出字,筆畫與顯示出來的字形也不相符。因此,批評者認爲,Unicode合併異體字並不可取。
收字過多
但是另一方面,Unicode收錄不少幽靈漢字,人們難以找到其出處,它們在實際生活上也極少機會使用,有些甚至是错讹字,或者僅是某一個人的名字用字,那個人不見得是名人,甚至可能已去世,卻永久成爲標準裏的字元,佔用了一個碼位。比如臺灣律師呂秋𧽚,他名字裏的「𧽚」字本應作「」,可是戶政人員誤聽他外公說的臺語,把「辵字邊」聽成「走馬邊」,外公又不敢更正。當事人長大後,才確認這是錯字,「五千年來從來沒人這麼寫過」[26]。但這字已永久收進Unicode中。又如香港增補字符集裏的許多人名用字,都被學者指出乃屬訛寫,或者是來歷不明的自創新字,多部權威字書都沒有收錄,學者批評把這些字收進字庫後將會永久遺害[27]。中文資訊界的李祥在其專欄批評當局「解決不了增補字集中上千錯字、白字、生造字的讀音問題」,呼籲「不要把香港增補字符集與申請ISO強迫聯繫在一起」[28]。然而,這些人名訛字亦已經收進Unicode中。這構成了收字過多的爭議。
也有批评认为Unicode收入大量错讹字及写法高度相似的同一字的不同字形本身就是不应该的。电脑文本本身永远不可能完全无损地记录文献,且文献本身也会因传抄制版等原因略有不同,如果把每个字的各种写法全部编码,會浪费空间。 完全无损地研究、记录文献只能通过查看原本或照相影印版来完成,把无损保存转嫁给编码是错误的。
現時Unicode把一些異體字分別編碼,帶來了檢索困難。只要寫法稍有不同,就无法检出,令使用戶检索字词时,必须反复检索其不同写法,造成重复劳动,对文献研究反而是种妨碍。例如Unicode中将「」和「𠒇」字安放在不同的碼位裏。在检索文献时,檢索「」字時就找不到「雷莊𠒇」,檢索「𠒇」字時就找不到「雷莊」,反而造成困扰[29]。
準則矛盾
對於同一部件,Unicode有分有合,原則不一致。如「」和「」、「」和「」都分離編碼,但「」和「」就整併了;「」和「」、「」和「」皆整併作一碼,而「」和「」又分開來,既令人混淆,亦令人無所適從。Unicode按原字集分離原則收字,只看各地區的既有編碼,不理會在文字學上同一部件的問題。可是用戶實際上在電腦輸入文字時,看到的是具體的字形,而不是編碼碼位,這就會讓人感到矛盾和困惑。
而且在Unicode「中日韓統一表意文字」的不同區域裏,官方也使用了不一致的併分尺度。早期的異體字時常獲分配正常碼位;後來常常只有兼容區的暫存編碼,使兼容區的字元在輸入和顯示時經常碰到問題;再後來則不時被直接整併並交由異體字選擇器處理。於是Unicode在編碼上的矛盾就更突顯。
已統一漢字
原則上ISO 10646只對字(Character),而非字形(Glyph)編碼。同一字各地可使用自己的標準寫法。以下使用HTML標示同一編碼的字在不同地區的寫法(但只是读者的浏览器所提供的字型,未必代表該地區的標準寫法)。
- 例子
| Unicode | 中文 | 日文 | 韓文 | 越文 | ||
|---|---|---|---|---|---|---|
| 中国大陸 | 臺灣 | 香港 | ||||
| U+623F | ||||||
| U+6C49 | [註 3] | |||||
| U+6E2F | ||||||
| U+6F22 | ||||||
| U+76F4 | ||||||
| U+7A97 | ||||||
| U+89D2 | ||||||
| U+8AA4 | ||||||
| U+8BEF | [註 3] | |||||
| U+8D77 | ||||||
| U+9AA8 | ||||||
註:不是所有網頁瀏覽器均可分辨全部HTML的語言代碼(Language Code)並使用不同字形。如非某一地区的使用者看到的字形和当地通用的字形一樣,表示该用户的瀏覽器不能分辨此標籤,或設定兩者以同一種字形顯示。
未統一漢字
有些字只是同一字在不同地區的寫法,理應統一,但因為原字集分離原則而只好分開編碼。由於KS X 1001、Big5、IBM 32、JIS X 0213、ARIB STD-B24、KPS 10721、CNS 11643中有太多字形非常接近,按Unicode標準應該統一,但是從編碼上分離的字。這些字只有正統的會編入正式字集(包括擴展區),不正統的編入「相容表意文字區」(Compatibility Ideographs)和位於「第二輔助平面」的「相容表意文字補充區」(Compatibility Ideographs Supplement)中。
範例: -{
| Unicode | 字 | Unicode | 字 | Unicode | 字 |
|---|---|---|---|---|---|
| U+4E1F | 丟 | U+4E22 | 丢 | ||
| U+514C | 兌 | U+5151 | 兑 | ||
| U+518A | 冊 | U+518C | 册 | ||
| U+5433 | 吳 | U+5434 | 吴 | U+5449 | 呉 |
| U+543F | 吿 | U+544A | 告 | ||
| U+5965 | 奥 | U+5967 | 奧 | ||
| U+5968 | 奨 | U+596C | 奬 | U+734E | 獎 |
| U+5986 | 妆 | U+599D | 妝 | ||
| U+59CD | 姍 | U+59D7 | 姗 | ||
| U+5C13 | 尓 | U+5C14 | 尔 | ||
| U+5F54 | 彔 | U+5F55 | 录 | ||
| U+6236 | 戶 | U+6237 | 户 | U+6238 | 戸 |
| U+63FA | 揺 | U+6416 | 搖 | U+6447 | 摇 |
| U+66A8 | 暨 | U+66C1 | 曁 | ||
| U+69D8 | 様 | U+6A23 | 樣 | ||
| U+6A2A | 横 | U+6A6B | 橫 | ||
| U+6B65 | 步 | U+6B69 | 歩 | ||
| U+7155 | 煕 | U+7199 | 熙 | ||
| U+7D55 | 絕 | U+7D76 | 絶 | ||
| U+7DA0 | 綠 | U+7DD1 | 緑 | ||
| U+9AEA | 髪 | U+9AEE | 髮 | ||
| U+9EAA | 麪 | U+9EAB | 麫 | ||
| U+9EBC | 麼 | U+9EBD | 麽 | ||
| U+9EC3 | 黃 | U+9EC4 | 黄 | ||
| U+9ED1 | 黑 | U+9ED2 | 黒 |
}- 自上表發表後,WG2亦調查過其他漢字[30],認為另一批屬於基本多文種平面的漢字,亦可考慮收編到ISO 10646 Annex S3。
技術問題
注释
- 這12個字放到兼容區不是因為和其他字同形或為異體,而是因為它們只收錄在廠商用字中,但未有收錄在官方標準(C-、T-、J-、K-Source)中。他們有獨立的形、音、義,即「獨一」(unique)[2]。
- 舊版“細明體”指Windows XP或以前版本之新細明體及細明體,其漢字寫法大體上遵從傳承字形。
- 某些碼位原來只有個別地區的字,但其他地區為兼容國際標準,逐漸將所有碼位的字亦納入其國家標準。
参考文献
- . 統一碼聯盟. [2018-06-03]. (原始内容存档于2018-06-11).
- Unicode 6.1,第410-411頁 页面存档备份,存于
- (PDF). [2020-03-24]. (原始内容存档 (PDF)于2019-08-19).
- (PDF). [2020-03-24]. (原始内容存档 (PDF)于2019-05-15).
- (PDF). [2020-03-24]. (原始内容存档 (PDF)于2019-05-15).
- (PDF). [2020-03-24]. (原始内容存档 (PDF)于2019-05-15).
- (PDF). [2020-03-24]. (原始内容存档 (PDF)于2019-05-15).
- 日本的「仝」本來被視為同上符號,位於中日韩符号和标点區;. fonts.jp. [2010-04-19]. (原始内容存档于2010-04-12).
- 收入中日韓相容表意文字
- . www.ibiblio.org. [2010-04-18]. (原始内容存档于2008-05-16).
- (PDF). [2011-09-09]. (原始内容存档 (PDF)于2012-05-09).
- (PDF). [2011-09-09]. (原始内容存档 (PDF)于2011-09-16).
- (PDF). [2010-06-06]. (原始内容存档 (PDF)于2011-07-21).
- . (原始内容 (PDF)存档于2018-01-15).
- (PDF). [2015年12月12日]. (原始内容 (PDF)存档于2015年1月4日).
- (PDF). [2015-06-19]. (原始内容存档 (PDF)于2015-06-25).
- (PDF). [2020-03-11]. (原始内容存档 (PDF)于2020-03-24).
- . [2020-03-11]. (原始内容存档于2020-03-11).
- 刻石錄:《Unicode摧殘正體字》 页面存档备份,存于、刻石錄:《不知丹青,枉談漢字》 页面存档备份,存于
- . [2019-02-08]. (原始内容存档于2018-08-02).
- . 統一碼聯盟. [2009-05-04]. (原始内容存档于2009-05-04).
- . libUnihan. [2009-05-04]. (原始内容存档于2012-03-21).
- 呂秋遠:《呂秋「走袁」》 页面存档备份,存于,刊《立場新聞》。
- 《政府通用字庫錯漏百出 收錄市民自創新字影響中文水平》,《太陽報》A6版,1999年10月13日
- . [2019-02-22]. (原始内容存档于2019-05-26).
- 散彈一號:《「𠒇」字係咩嚟?——港姐冠軍帶出嘅哲學問題》 页面存档备份,存于,刊《輔仁媒體》。
- (.zip). [2019-06-22].
- (PDF). [2008-02-17]. (原始内容存档 (PDF)于2007-06-12).
- (PDF). [2015-06-20]. (原始内容 (PDF)存档于2015-06-20).
- (PDF). [2015-06-20]. (原始内容 (PDF)存档于2015-06-20).
外部連結
- 統一碼裏中日韓表意文字和相關字符淺說 页面存档备份,存于
- CJK-CODE 页面存档备份,存于
- UTF-8 and Unicode FAQ for Unix/Linux 页面存档备份,存于
- 中華民國教育部異體字字典附錄-中日韓共用漢字表 页面存档备份,存于
- 查「Unicode 編碼」或「教育部異體字字典字號」 页面存档备份,存于(CBETA 中華電子佛典協會)
- Unicode(統一碼)
- 漢字統合歷史 页面存档备份,存于
- 統漢字搜尋工具 页面存档备份,存于
- 表意文字變體數據庫 页面存档备份,存于
- Unicode Roadmap to the TIP 页面存档备份,存于
- 中日韓統一表意文字 页面存档备份,存于(PDF,34.0MB)
- 中日韓兼容漢字 页面存档备份,存于(PDF,762kB)
- 中日韓兼容漢字補充 页面存档备份,存于(PDF,601kB)
- 擴展A區漢字 页面存档备份,存于(PDF,6.58MB)
- 擴展B區漢字 页面存档备份,存于(PDF,38.7MB)
- 擴展C區漢字 页面存档备份,存于(PDF,3.16MB)
- 擴展D區漢字 页面存档备份,存于(PDF,215kB)
- 擴展E區漢字 页面存档备份,存于(PDF,3.44MB)
- 擴展F區漢字 页面存档备份,存于(PDF,4.33MB)
- 擴展G區漢字 页面存档备份,存于(PDF,2.13MB)
